Go 程序是怎样跑起来的?
3月 31, 2021
Go 程序是怎么跑起来的?面对问题我第一反应是,Go 是静态编译型语言,和 C 语言一样,就是编译、链接那一套,尤其是最近对着 Go 的一些资料看感觉又学习了一遍编译原理。编译原理的内容本身就很深,本文仅以我暂时理解到的视角进行总结,参考资料列在了最下面。
编译器总览 #
典型的编译器(Compiler)如 LLVM 分为编译器前端、优化器和编译器后端。其中,前端专注于词法分析、解析语法和语义分析,然后生成一个标准化的中间代码(IR)表示形式,生成的 IR 一般会有优化器进行分析、优化(精简、替换),最终产出一个可以供编译器后端使用的 IR。后端会遍历 IR 并针对目标机器类型输出汇编代码,同时后端还会确定哪些值能够驻留在寄存器中,哪些值需要放入内存中,并插入代码来实施相应的决策。
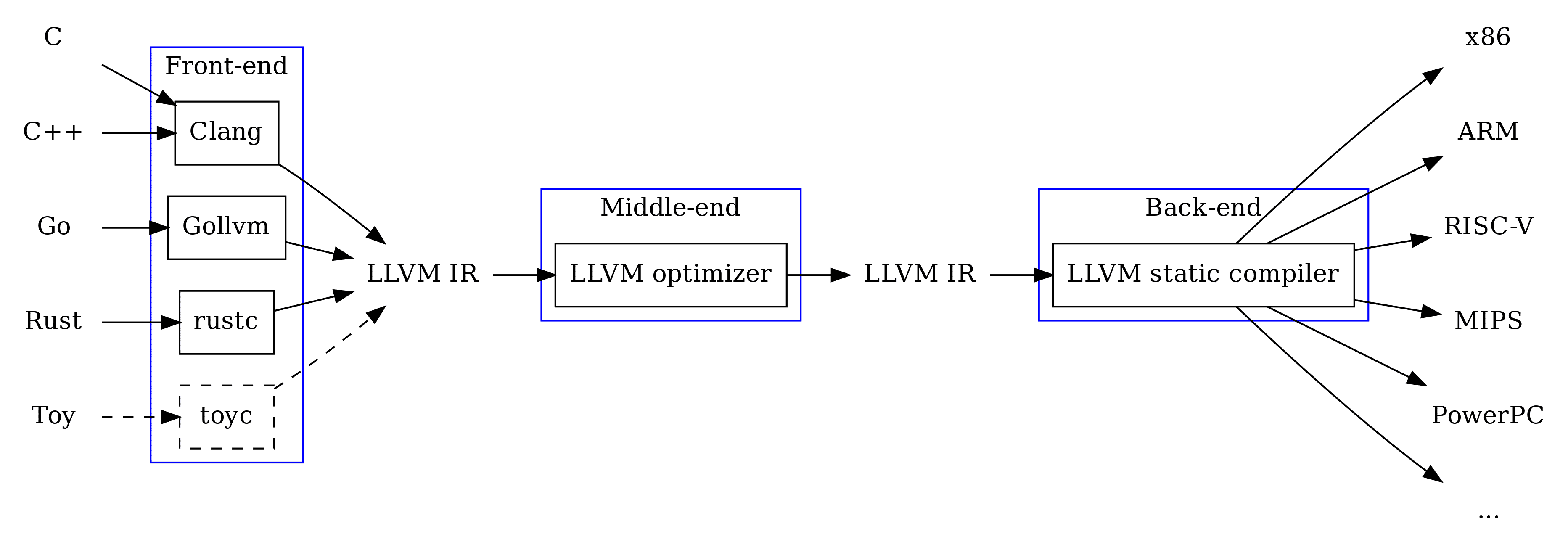
由于很多编译原理的资料都是以 C 语言为标准来描述编译原理,这里也按照 C 语言来介绍一下编译过程。以 main.c 为例:
#include <unistd.h>
#include <stdio.h>
int main()
{
int pid = fork();
if (pid == -1)
return -1;
if (pid)
{
printf("I am father, my pid is %d\n", getpid());
return 0;
} else {
printf("I am child, my pid is %d\n", getpid());
return 0;
}
}
C 语言中会使用 gcc 将源码文件编译成汇编代码:
gcc -S main.c -o main.s
得到的 main.s 就是编译器生成的汇编代码,也是一种中间代码:
.section __TEXT,__text,regular,pure_instructions
.build_version macos, 12, 0 sdk_version 12, 3
.globl _main ; -- Begin function main
.p2align 2
_main: ; @main
.cfi_startproc
; %bb.0:
sub sp, sp, #32
stp x29, x30, [sp, #16] ; 16-byte Folded Spill
add x29, sp, #16
.cfi_def_cfa w29, 16
.cfi_offset w30, -8
.cfi_offset w29, -16
stur wzr, [x29, #-4]
bl _fork
str w0, [sp, #8]
ldr w8, [sp, #8]
adds w8, w8, #1
b.ne LBB0_2
b LBB0_1
LBB0_1:
mov w8, #-1
stur w8, [x29, #-4]
b LBB0_5
LBB0_2:
ldr w8, [sp, #8]
cbz w8, LBB0_4
b LBB0_3
... 省略
然后汇编器负责将汇编代码转变成机器可以执行的指令,每一个汇编语句几乎都对应了一条机器指令。所以汇编器的工作比较简单,只需要按照对应关系一一翻译就好了,最后输出机器码,也叫目标文件(object code)、二进制文件(binaries)。
C 语言中通过 as 命令来将汇编代码转变成目标文件。
as main.s -o main.o
或者
gcc -c main.s -o main.o以十六进制查看文件 main.o 可以看到类似这样的编码,这就是目标文件:
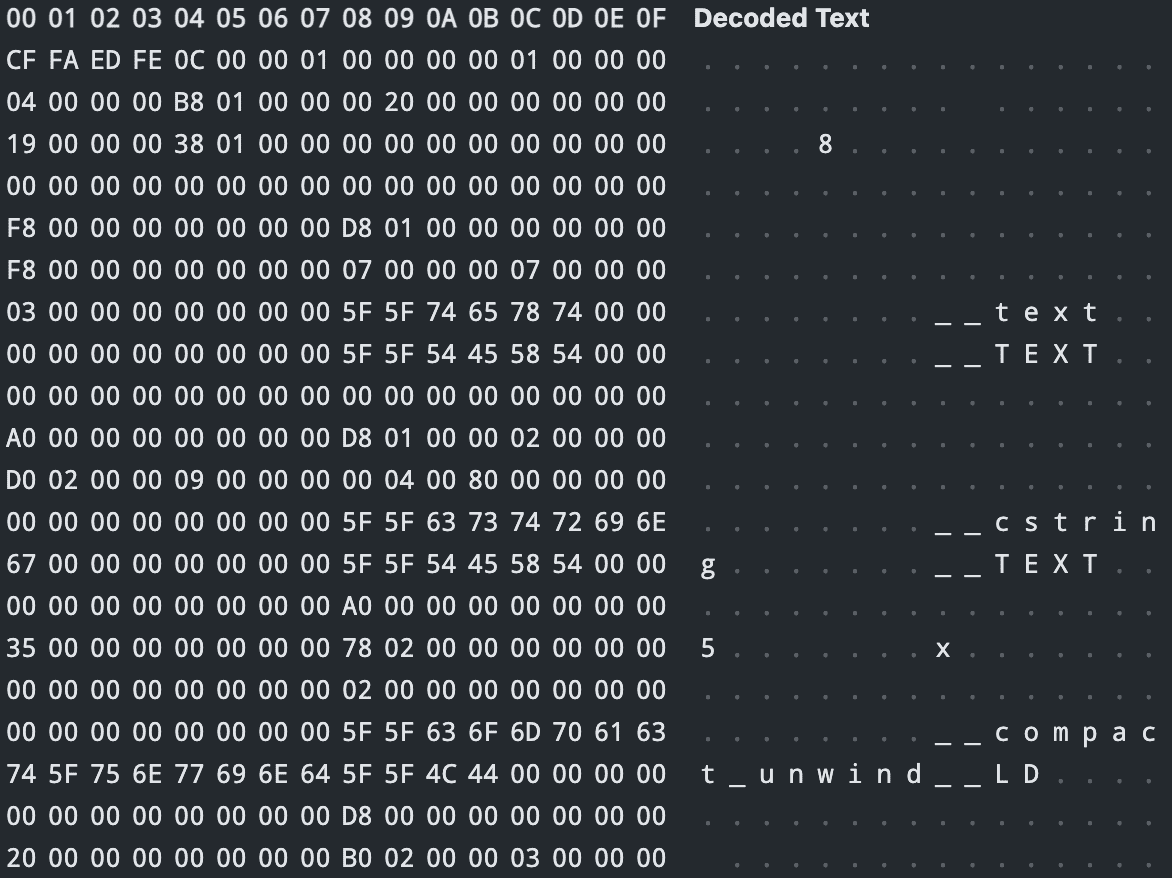
得到目标文件之后,main.o 仍然不是可执行文件。设想一下,如果源代码里引用了别的模块的代码,链接器则需要将各个模块组装起来,从原理上看,它的工作就是把一些指令对其他符号地址的引用加以修正,所以目标文件也是一种“模块”。
还有一个场景:一个存放在硬盘的指令集合(目标文件),应该如何放到内存中,并从指定的内存位置开始执行?这个地址和空间分配的工作也是由链接器来完成的。
经过链接,就可以得到了可执行文件 a.out ,通常使用 ld 命令。也可以直接通过 gcc main.c 得到 a.out。
Go 编译器介绍 #
Go 语言的编译器一般缩写为小写的 gc(go compiler),需要和大写的 GC(垃圾回收)进行区分。最初 gc 也是拿 C 语言来实现的,后来 Go 在 v1.5 版本实现了自举(Bootstrapping),目前和 Go 编译器相关的代码都位于 src/cmd/compile/internal 目录下。
You may sometimes hear the terms “front-end” and “back-end” when referring to the compiler. Roughly speaking, these translate to the first two and last two phases we are going to list here. A third term, “middle-end”, often refers to much of the work that happens in the second phase.
在 Go 语言编译器的 README 中,(我猜测)由于前端和后端都是自己写,所以没有强调编译器的前端(font-end)和后端(back-end)概念,而是强调对应四个阶段的前两个阶段(first two phases)和后两个阶段(last two phases),至于文档中的术语“中端”(middle end),通常指的是第二个阶段发生的事情,所以下面的目录就不能按照前端和后端区分了,知道属于哪部分阶段就可以。
- 第一阶段:通过词法分析和语法分析对文件进行扫描并生成抽象语法树;
- 第二阶段:对抽象语法树并进行类型检查(语义分析);
- 第三阶段:将抽象语法树生成 SSA;
- 第四阶段:将 SSA 生成机器码;
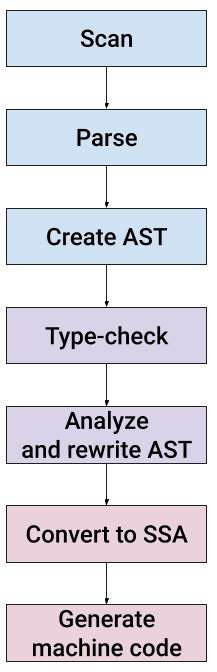
Go 语言编译器的执行流程可细化为多个阶段,包括词法分析、语法分析、抽象语法树构建、类型检查、变量捕获、函数内联、逃逸分析、闭包重写、遍历函数、SSA生成等,下面按顺序讲一下。
词法分析(lexical analysis) #
词法分析器(lexical analyzer,lexer)也叫扫描器,源代码程序被输入扫描器(Scanner),扫描器的任务就是就是简单地进行词法分析,通常运用有限状态机(Finite State Machine)的算法将源码中的字符序列分割成一系列的记号(Token),这个过程也叫记号/符号化(Tokenization)。
Token 一般分为:关键字、标识符、字面量、运算符等。比如 sum:=3+2 可能被解析成:
| token | 记号类型 |
|---|---|
| sum | 标识符 |
| := | 赋值操作符 |
| 3 | 数字 |
| + | 加法操作符 |
| 2 | 数字 |
传统的编译工具箱里,有一个叫 lex 的程序可以实现词法扫描,它会按照用户之前描述好的词法规则将输入的字符串分割成一个个记号,这样开发者就无须为每个编译器开发一个独立的词法扫描器,而是根据需要改变词法规则就可以了。
早期 Go 也是使用 lex 进行词法分析,但是最后还是使用 Go 自己写的词法分析器解析自己,关键词:Token,Scanner。
语法分析(syntax analysis) #
语法分析器(Grammar Parser)将使用上下文无关文法对 Scanner 产生的 token list 进行语法分析,最后每个文件会产生一个独立的抽象语法树(AST)。语法分析的分析方法一般分为自顶向下和自底向上两种,这两种方式会使用不同的方式对输入的 Token 序列进行推导:
- 自顶向下分析:可以被看作找到当前输入流最左推导的过程,对于任意一个输入流,根据当前的输入符号,确定一个生产规则,使用生产规则右侧的符号替代相应的非终结符向下推导,比如 LL 文法;
- 自底向上分析:语法分析器从输入流开始,每次都尝试重写最右侧的多个符号,这其实是说解析器会从最简单的符号进行推导,在解析的最后合并成开始符号,比如 LR(0)、SLR、LR(1) 和 LALR(1) 文法;
与词法分析有 lex 一样,语法分析也有一个现成的工具叫 yacc(Yet Another Compiler Compiler),它可以根据用户给定的语法规则对输入的记号序列进行解析,从而构建出一个语法树,所以它又被成为“编译器的编译器”(Compiler Compiler)。
Go 语言解析器使用了 LALR(1) 的文法来解析词法分析过程中输出的 Token 序列,具体的核心逻辑在 cmd/compile/internal/syntax/nodes.go 和 cmd/compile/internal/syntax/parser.go 中。
语义分析(semantic analysis) #
当拿到一组文件的抽象语法树(AST)之后,语义分析器(semantic analyzer)会对语法树中的语义进行类型检查,比如一些 Go 程序看起来没有语法错误,但是会因为没有类型转换而无法运行:
func main() {
a := 1
b := 1.0
a = b
fmt.Println(a)
}
编译器所能分析的语义是静态语义(static semantic),就是指在编译期间可以确定的语义,与之对应的就是动态语义(dynamic semantic),是指只能在运行期才能确定的语义,比如下面这个例子就是动态语义分析时会遇到不能除以 0 的错误。
func main() {
a := 10
b := a
fmt.Println((a + b) / (a - b))
}
Go 语言的类型检查核心代码在 cmd/compile/internal/types2 中,会按照以下的顺序分别验证和处理不同类型的节点:
- 常量、类型和函数名及类型;
- 变量的赋值和初始化;
- 函数和闭包的主体;
- 哈希键值对的类型;
- 导入函数体;
- 外部的声明;
经过语义分析后,就可以认为当前文件中的代码不存在语法错误和类型错误的问题了,编译器就会将整个语法树转换成中间代码,它是语法树的顺序表示。
中间代码生成 #
编译器前端的工作都完成后,编译器会将输入的抽象语法树转换成中间代码,也叫中间表示(Intermediate Representation,IR),常见的中间代码有:三地址码,P-code 代码。中间代码使得编译器可以分为前端和后端。编译器前端负责产生机器无关的中间代码,编译器后端负责将中间代码转换成目标机器代码。这样对于一些可以跨平台的编译器而言,它们可以针对不同的平台使用同一个前端和针对不同机器平台的数个后端。
生成 IR(IR construction) #
Go 编译器在完成类型检查之后,首先会生成一颗基于 AST 的 IR Tree 进行函数内联、逃逸分析等操作,然后再生成基于 SSA 的 IR 进行编译。源码主要是四个方面:
cmd/compile/internal/types(compiler types)cmd/compile/internal/ir(compiler AST)cmd/compile/internal/typecheck(AST transformations)cmd/compile/internal/noder(create compiler AST)
推荐阅读
优化(Optimization) #
中间代码的存在是非常有必要的,从编译原理角度讲,除了更容易翻译成机器码之外,对中间代码的优化和分析相比直接分析高级语言更容易,当然相比机器码也会更容易。所以编译器在中间代码生成后一般都有优化器的概念,优化器是一个 IR 到 IR 的转换器,试图在某些方面改进 IR 程序,它可以分析 IR 并重写 IR,优化器重写 IR 可以使后端生成一个可能更快速或更小的目标程序,优化器还有其他目标,诸如产生更少缺页异常或耗能较少的程序。
Several optimization passes are performed on the IR representation: dead code elimination, (early) devirtualization, function call inlining, and escape analysis.
Go 编译器中 IR 会在这个阶段(gc 管这个阶段叫 Middle end)进行几轮优化,下面介绍一些 go 编译器中的优化步骤。
变量捕获 #
变量捕获主要是针对闭包场景而言的,由于闭包函数中可能引用闭包外的变量,因此变量捕获需要明确在闭包中通过值引用或地址引用的方式来捕获变量。
函数内联 #
函数内联(function call inlining)指将较小的函数直接组合进调用者的函数。函数内联的优势在于,可以减少函数调用带来的开销。
对于Go语言来说,函数调用的成本在于参数与返回值栈复制、较小的栈寄存器开销以及函数序言部分的检查栈扩容(Go语言中的栈是可以动态扩容的),同时,函数内联是其他编译器优化(例如无效代码消除)的基础。相关代码在 cmd/compile/internal/inline。
无效代码消除 #
编译器原理中,死码消除(Dead code elimination)是一种编译优化技术,它的用途是移除对程序执行结果没有任何影响的代码。移除这类的代码有两种优点,不但可以减少程序的大小,还可以避免程序在执行中进行不相关的运算行为,减少它执行的时间。不会被执行到的代码(unreachable code)以及只会影响到无关程序执行结果的变量(Dead Variables),都是死码(Dead code)的范畴。
相关代码在 cmd/compile/internal/deadcode。
逃逸分析 #
逃逸分析(escape analysis)是Go语言中重要的优化阶段,用于标识变量内存应该被分配在栈区还是堆区。
在传统的 C 或 C++ 语言中,开发者经常会犯的错误是函数返回了一个栈上的对象指针,在函数执行完成,栈被销毁后,继续访问被销毁栈上的对象指针,导致出现问题。
Go 语言能够通过编译时的逃逸分析识别这种问题,自动将该变量放置到堆区,并借助 Go 运行时的垃圾回收机制自动释放内存。编译器会尽可能地将变量放置到栈中,因为栈中的对象随着函数调用结束会被自动销毁,减轻运行时分配和垃圾回收的负担。
在 Go 语言中,开发者模糊了栈区与堆区的差别,不管是字符串、数组字面量,还是通过 new、make 标识符创建的对象,都既可能被分配到栈中,也可能被分配到堆中。相关代码在 cmd/compile/internal/escape。
闭包重写 #
在完成逃逸分析后,下一个优化的阶段为闭包重写,其核心逻辑位于gc/closure.go中。闭包重写分为闭包定义后被立即调用和闭包定义后不被立即调用两种情况。在闭包被立即调用的情况下,闭包只能被调用一次,这时可以将闭包转换为普通函数的调用形式。
如果闭包定义后不被立即调用,而是后续调用,那么同一个闭包可能被调用多次,这时需要创建闭包对象。
遍历函数(Walk) #
IR 表示的最后一步是进行“walk”,它会遍历函数中的声明和表达式,主要有两个目的:
- 它将复杂的语句分为单个的、简单的语句,引入临时变量并遵循原有的求值顺序。
- 它将一些语言中的关键字转换为具体的函数执行。比如
switch,map和channel等操作。
相关代码在 cmd/compile/internal/gc/walk.go 中。
SSA 生成(IR -> SSA) #
In this phase, IR is converted into Static Single Assignment (SSA) form, a lower-level intermediate representation with specific properties that make it easier to implement optimizations and to eventually generate machine code from it.
经过 walk 系列函数的处理之后,抽象语法树就不会改变了。编译器会将 IR 转换为下一个重要的中间表示形态,称为静态单赋值(Static Single-Assignment,SSA)形式,这是一种具有特定属性的低级中间表示形式(算是三地址码的一种变体),可以更容易地实现优化。SSA 在 Go 1.7 中被正式引入并替换了之前的编译器后端,用于最终生成更有效的机器码。
至此,SSA 将又进行一系列编译器后端里的优化技术。
目标代码生成 #
机器码就是目标代码(object file),其文件也叫二进制文件(但一般不是真的二进制代码),由汇编器生成,由于各类 CPU 的指令集不同,目标代码最终也会被生成不同的机器指令。
SSA 降级 #
机器码的生成过程其实是对 SSA 中间代码的降级(lower)过程,其中将近 50 轮处理的过程中,lower 以及后面的阶段都属于 SSA 降级这一过程,这么多轮的处理会将 SSA 转换成机器特定的操作。这也是代码进入汇编器前的最后一个步骤。
在 SSA 降级阶段,就开始执行与特定指令集有关的优化,并最终生成与特定指令集有关的指令和寄存器分配方式,达到接近汇编代码的程度。
通过 GOSSAFUNC="main" go build main.go 命令查看 SSA 的降级过程,从第一轮中间代码(start)经过几十轮优化再到 lower 再到最终的 SSA(genssa)。

在 SSA 完成降级后,编译器将调用与特定指令集有关的汇编器将 SSA 代码将被转换成汇编代码。
汇编器(Assembler) #
汇编器是将汇编语言翻译为机器语言的程序,Go 语言的汇编器是基于 Plan 9 汇编器的输入类型设计的,internal/obj 目录中包含了汇编与链接的核心逻辑,内部有许多与机器码生成相关的包。
package main
import (
"fmt"
)
func main() {
a := 10
b := a
fmt.Println((a + b) / (a - b))
}
对于上面这样一段程序,可以使用 go tool compile -S main.go 来将源码编译成汇编代码。
"".main STEXT size=48 args=0x0 locals=0x8 funcid=0x0
0x0000 00000 (main.go:7) TEXT "".main(SB), ABIInternal, $16-0
0x0000 00000 (main.go:7) MOVD 16(g), R1
0x0004 00004 (main.go:7) PCDATA $0, $-2
0x0004 00004 (main.go:7) MOVD RSP, R2
0x0008 00008 (main.go:7) CMP R1, R2
0x000c 00012 (main.go:7) BLS 36
0x0010 00016 (main.go:7) PCDATA $0, $-1
0x0010 00016 (main.go:7) MOVD.W R30, -16(RSP)
0x0014 00020 (main.go:7) MOVD R29, -8(RSP)
0x0018 00024 (main.go:7) SUB $8, RSP, R29
0x001c 00028 (main.go:7) FUNCDATA ZR, gclocals·33cdeccccebe80329f1fdbee7f5874cb(SB)
0x001c 00028 (main.go:7) FUNCDATA $1, gclocals·33cdeccccebe80329f1fdbee7f5874cb(SB)
0x001c 00028 (main.go:10) PCDATA $1, ZR
0x001c 00028 (main.go:10) CALL runtime.panicdivide(SB)
0x0020 00032 (main.go:10) HINT ZR
0x0024 00036 (main.go:10) NOP
0x0024 00036 (main.go:7) PCDATA $1, $-1
0x0024 00036 (main.go:7) PCDATA $0, $-2
0x0024 00036 (main.go:7) MOVD R30, R3
0x0028 00040 (main.go:7) CALL runtime.morestack_noctxt(SB)
0x002c 00044 (main.go:7) PCDATA $0, $-1
0x002c 00044 (main.go:7) JMP 0
0x0000 81 0b 40 f9 e2 03 00 91 5f 00 01 eb c9 00 00 54 ..@....._......T
0x0010 fe 0f 1f f8 fd 83 1f f8 fd 23 00 d1 00 00 00 94 .........#......
0x0020 1f 20 03 d5 e3 03 1e aa 00 00 00 94 f5 ff ff 17 . ..............
rel 0+0 t=25 type.int+0
rel 0+0 t=25 type.*os.File+0
rel 28+4 t=10 runtime.panicdivide+0
rel 40+4 t=10 runtime.morestack_noctxt+0
...省略
将这段代码与上面的 genssa 对比,还是有区别的。
链接器(linker) #
目标代码还不是可执行文件,后面还需要链接器将目标文件链接在一起生成可执行文件或库文件。通过 go build main.go 编译可以直接得到一个十六进制的可执行文件 main。
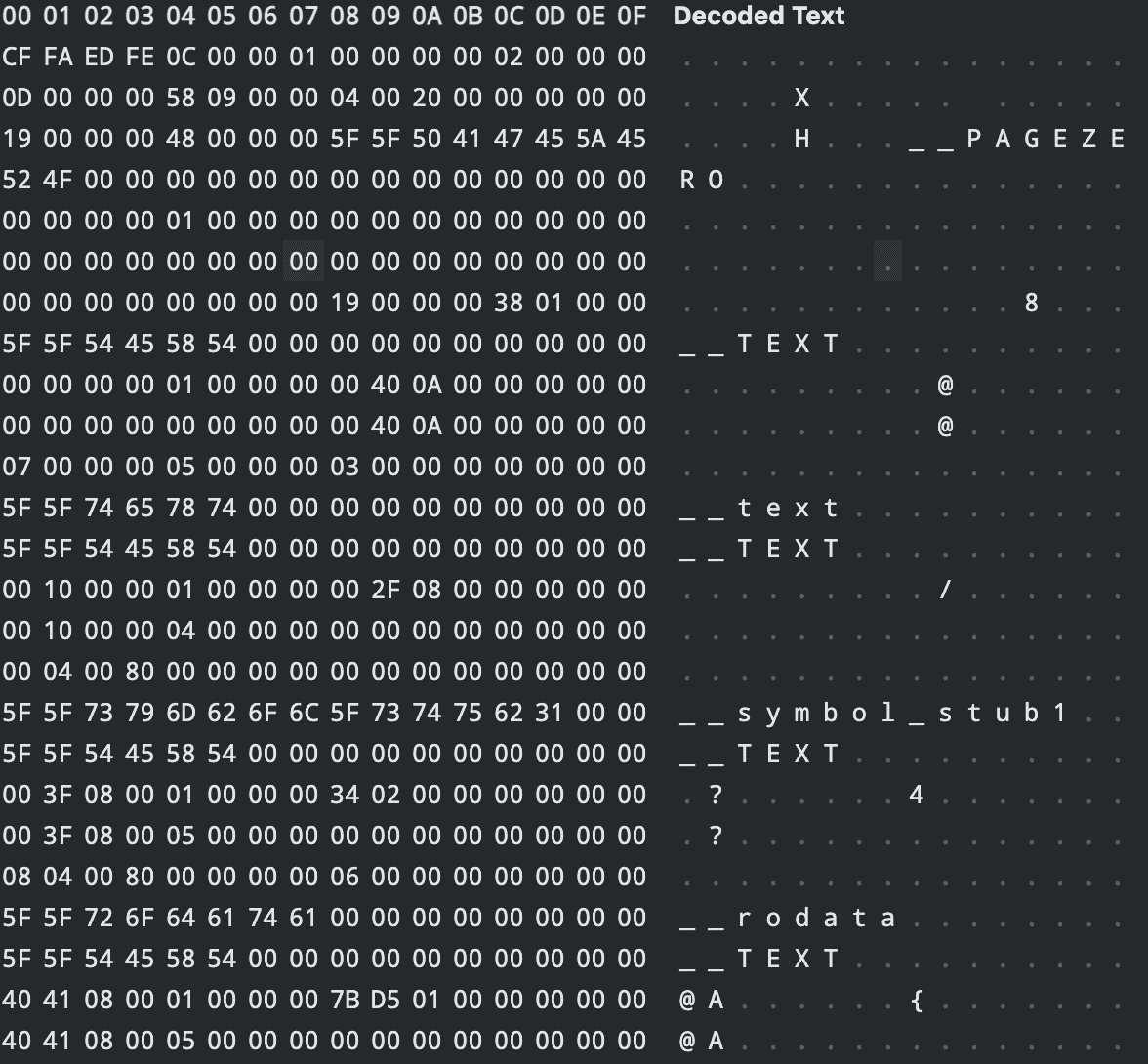
至此,对一个 go 程序从编译到运行的步骤,终于梳理完成了,虽然不算是源码级的分析,但也基本知道一个大致流程,以后有时间再慢慢研究一些 AST/IR/SSA 优化技术,研究这个话题之前我甚至觉得我快精通 Go 了,看完觉得还是差远了,要学的还有很多。
参考 #
建议先看官方文档了解一下流程。
- https://github.com/golang/go/blob/master/src/cmd/compile/README.md
- https://github.com/golang/go/blob/master/src/cmd/compile/internal/ssa/README.md
网络上和一些书上也有很多源码级分析资料。
- https://zhuanlan.zhihu.com/p/71993748
- https://draveness.me/golang/
- https://oftime.net/2021/02/14/ssa/
- Golang 编程器代码简析
- Go compiler internals - Part 1
- Go compiler internals - Part 2
推荐个线上 SSA 分析工具 https://golang.design/gossa
Plan 9 汇编入门 https://xargin.com/plan9-assembly/