Go 语言的 MPG 并发调度模型
12月 21, 2020
Golang 的高并发能力是通过协程 goroutine 实现的,在 Go 语言的开发中,每涉及到 goroutine 的相关功能实现时,都会意识到自己需要对 MPG 的模型有一个大概的了解,在此基础上才能做好开发上的决策,本篇也即为 MPG 并发调度模型的学习笔记了。
进程、线程和协程 #
要对 goroutine 的调度器深入了解,需要先了解一下进程、线程的基础知识。
进程 #
进程作为拥有资源分配的最小单位,它为每个程序维护着运行时的各种资源,比如进程ID、进程的页表、进程执行现场的寄存器值、进程各个段地址空间分布信息以及进程执行时的维护信息等,它们在程序的运行期间会被经常或实时更新。
进程作为用户操作的实体,它贯穿操作系统的整个生命周期,而程序是由若干段二进制码组成的。进程可以说是程序的运行态抽象,即运行于处理器中的二进制码叫作进程,保存在存储介质中的二进制码叫作程序。
Linux 用 fork 方法创建进程,不同的进程具有不同的进程 ID(PID)。
线程 #
一个进程会至少包含一个线程,线程是操作系统调度时的最基本单元,每个线程都会占用 1M 以上的内存空间,而且在线程切换时也会消耗更多的内存和时间。操作系统的线程状态一般分为就绪态、运行态、睡眠态、僵尸态和终止态。线程之间一般通过同步原语进行并发资源访问的管理。
Linux 用 clone 方法创建线程,线程也称为是轻量级的进程。
协程 #
协程并不是 Go 独有的概念,在很多其他语言也存在,但是只有 Go 在语言层面对协程直接提供如此优雅的支持。每个协程初始化后的内存大小只有 2k,比线程小的多,而且可以动态扩容。线程和协程是 M : N 的关系,即 M 线程上可能有 N 个协程。
调度模型 #
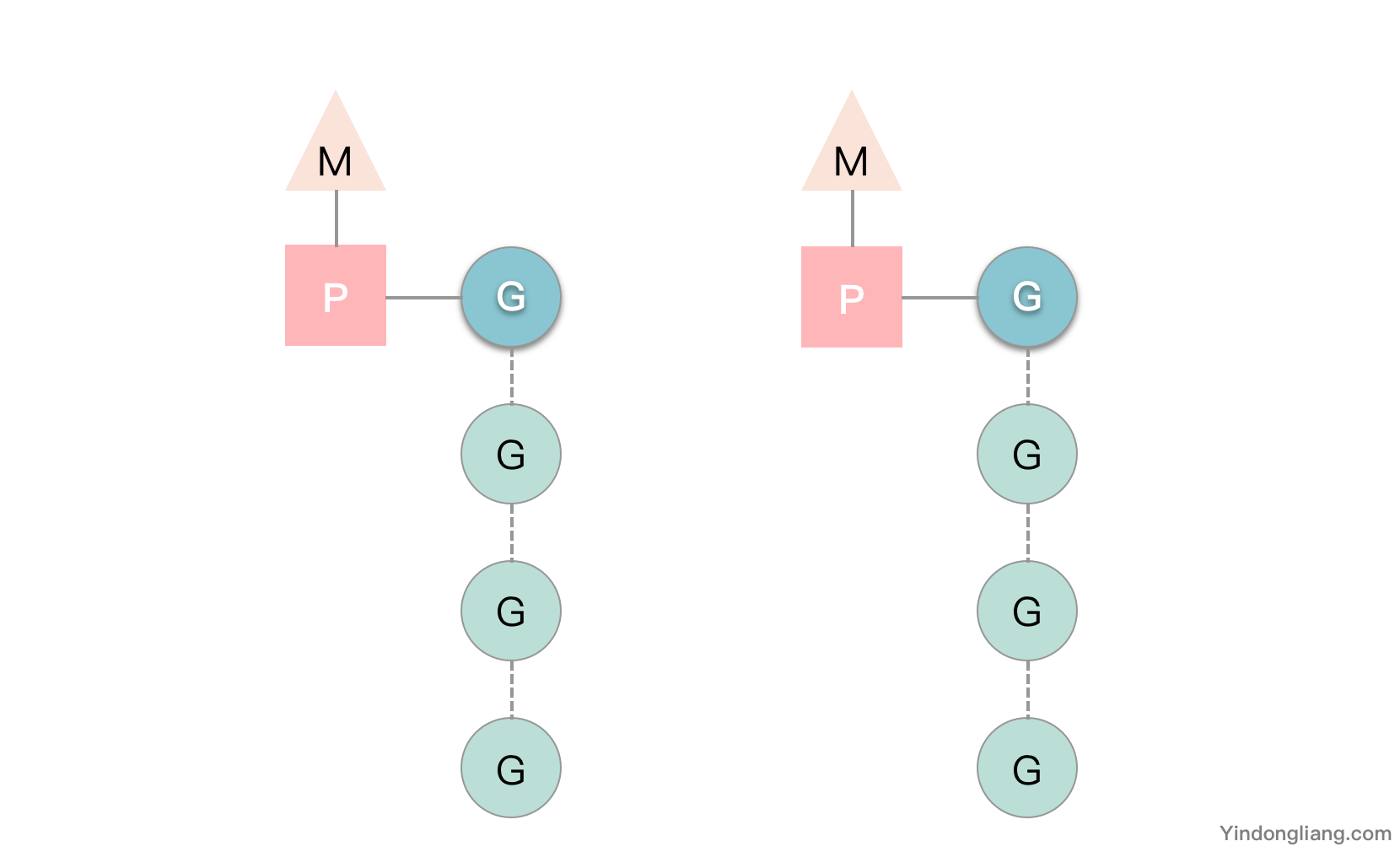
图中 G 是 goroutine,它是一个待执行的任务, M 是线程,由操作系统调度和管理,P 是运行在线程上的逻辑处理器,它们的代码定义在 runtime.runtime2.go 中,下面详细介绍。
G #
G,就是 Goroutine,即我们在 Go 程序中使用 go 关键字创建的执行体,Go 程序中每个 go 关键字都会创建一个 goroutine,是调度器中待执行的任务。
因为 runtime.g 中涉及了非常多的字段,在一起不太好说,下面开始拆开逐个分析。
栈内存 stack #
type g struct {
stack stack
stackguard0 uintptr
}
type stack struct {
lo uintptr
hi uintptr
}
g.stack 字段描述了当前 goroutine 的栈内存范围 [stack.lo, stack.hi)。
stackguard0 用于调度器抢占式调度。
调度器 sched #
type g struct {
sched gobuf
}
sched 存储 goroutine 的调度相关的数据,即 gobug 格式的内容;
执行现场 gobuf #
当协程进行上下文切换时,上一个协程的执行现场需要存储在 g.gobuf 结构体中,g.gobuf 结构体主要保存 CPU 中几个重要的寄存器值,分别是 rsp、rip、rbp。
type g struct {
sched gobuf
}
type gobuf struct {
sp uintptr // CPU 的 rsp 寄存器的值
pc uintptr // CPU 的 rip 寄存器的值
g guintptr // 记录当前的 gobuf 属于哪个 goroutine
ret sys.Uintreg // 保存系统调用的返回值
bp uintptr // 记录 CPU 的 rbp 寄存器的值
}
其中:
rsp寄存器始终指向函数调用栈顶;rip寄存器执行程序要执行的下一条指令的地址;rbp存储了函数栈帧的起始位置。
当 goroutine 被恢复时,调度器代码就会把这个 G 对象里的变量恢复到寄存器中让 CPU 执行。
panic 和 defer #
type g struct {
_panic *_panic // 最内侧的 panic 结构体
_defer *_defer // 最内侧的延迟函数结构体
}
我们知道 panic 和 defer 在程序中的声明和调用是入栈和出栈的形式,它们在底层是以链表来实现的,每一个 goroutine 上都持有分别存储 defer 和 panic 对应结构体的链表。
关联 M #
type g struct {
m *m
}
m 为 g 所占用的线程。
状态流转 #
type g struct {
atomicstatus uint32
}
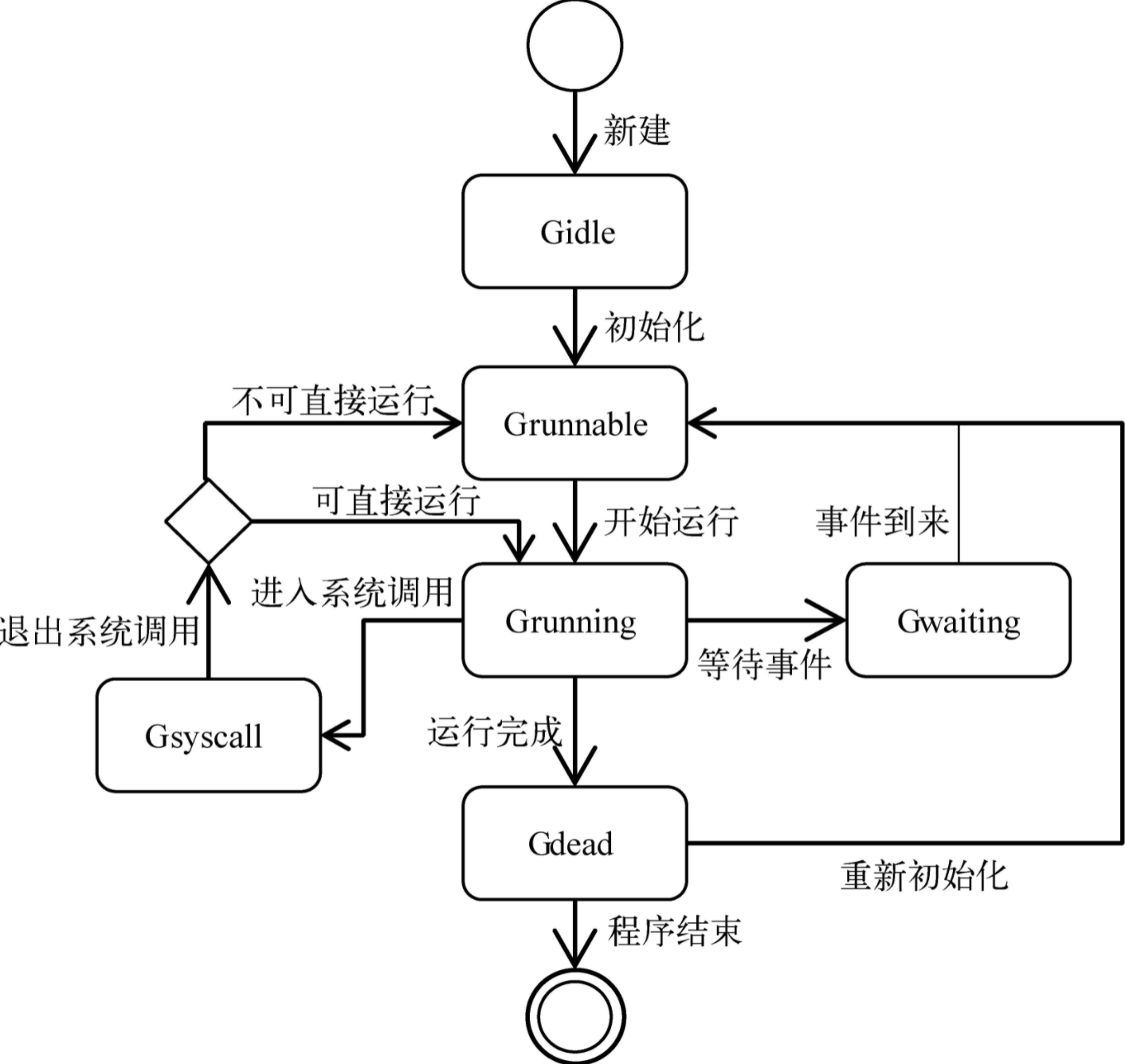
g.atomicstatus 中记录了 goroutine 当前的状态,主要是以下的几种:
| 状态 | 描述 |
|---|---|
_Gidle | 刚刚被分配并且还没有被初始化,初始化以后会变为 _Gdead 状态,_Gdead 也是协程被销毁时的状态。 |
_Grunnable | 没有执行代码,没有栈的所有权,存储在运行队列中,等待被运行。 |
_Grunning | 表示当前协程正在被运行,拥有栈的所有权,被赋予了内核线程 M 和处理器 P。 |
_Gsyscall | 正在执行系统调用,拥有栈的所有权,没有执行用户代码,被赋予了内核线程 M 但是不在运行队列上。 |
_Gwaiting | 由于运行时而被阻塞,没有执行用户代码并且不在运行队列上,但是可能存在于 Channel 的等待队列上。 |
_Gdead | 没有被使用,没有执行代码,可能有分配的栈。 |
_Gcopystack | 栈正在被拷贝,没有执行代码,不在运行队列上。 |
_Gpreempted | 由于抢占而被阻塞,没有执行用户代码并且不在运行队列上,等待唤醒。 |
_Gscan | GC 正在扫描栈空间,没有执行代码,可以与其他状态同时存在。 |
goroutine 的状态流转非常复杂,他们之间大体如下图。
M #
M 是 Machine,即传统意义上进程的线程,由操作系统调度和管理,M 需要持有 P 才能执行任务 G,注意 M 并不是线程本身,而是与运行时为 M 创建的线程相绑定。M 本身是无状态的,是否为空闲仅以它是否存在与调度器的空闲 M 列表中为依据。
除了 M0 是由 main goroutine 创建的,创建另外 M 的原因主要是没有足够的 M 来关联 P 并运行其中的 G,另外运行时系统执行系统监控和垃圾回收也会导致创建新的 M。
g0 #
type m struct {
g0 *g // goroutine with scheduling stack
}
每个线程中都有一个特殊的协程 g0,g0 负责执行协程调度的一系列运行时代码,而一般的协程用来执行用户代码,当用户协程退出或被抢占时,需要重新运行协程调度,这是就会从用户协程 g 切换到 g0,g0 会调度出另一个用户协程 g,从而开始执行新的用户协程,循环往复。
curg #
type m struct {
curg *g // current running goroutine
}
curg 就是 M 当前执行的用户协程。
线程本地存储 tls #
type m struct {
tls [6]uintptr // thread-local storage (for x86 extern register)
}
操作系统中,线程中存储的局部变量只对当前线程可见,Go 语言的运行时的调度器使用线程本地存储将线程与运行时的 M 结构体绑定在一起。结构体 M 中 m.tls 的是线程本地存储的地址,同时 tls[0] 存储的是当前线程正在运行的协程 g 的地址。因此,在任何一个线程内部,都可以获取到当前线程上的协程 g、结构体 m、和处理器 p、特殊协程 g0 等。
持有 P #
type m struct {
p puintptr
nextp puintptr
oldp puintptr
}
M 被创建之后就会关联一个 P,M 与 P 的关系体现在以上三个字段中,其中:
p:表示正在运行代码的处理器。nextp:表示暂存于当前 M 的、有潜在关系的处理器 P,M 创建之初,这个 P 就会被关联。oldp:执行调用栈之前使用 M 的处理器。
P #
处理器(Processor)P 不是指 CPU,而是运行在线程上的调度管理器,是 G 能够在 M 上运行的关键,具有调度 goroutine 的能力。只有当 M 与一个 P 关联后才能执行 Go 代码,runtime.p 是处理器的运行时表示。P 的数量由环境变量 GOMAXPROCS 或 runtime.GOMAXPROCS() 函数指定。
Go 语言的运行时会适时地让 P 与不同的 M 建立或断开关联,以使 P 中那些可运行的 G 能够在需要的时候获得运行时机,当 P 不再与 M 关联时,它会被加入全局的空闲 P 列表 runtime.sched.pidle。
运行队列 #
type p struct {
runqhead uint32
runqtail uint32
runq [256]guintptr
runnext guintptr
}
处理器 P 除了持有线程,还有一个 goroutine 运行队列,源码中用 runq 相关的字段表示,而 runnext 是线程下一个要执行的 goroutine。除了这个队列外,还有一个全局的 runq 队列,由多个处理器共享。
一般来说,P 中的 G 创建的协程会加入本地的 runq 中,如果本地已满,则会加入全局的队列,处理器 P 除了调度本地队列中的协程,还会周期地从全局队列中获取 goroutine 来调度。
GOMAXPROCS #
通过 GOMAXPROCS 可以设置 Go 程序最多运行的 P 的数量,默认情况下它会是主机 CPU 的核数。在确定了这个值以后,运行时会根据这个值初始化全局的 P 列表 runtime.allp。
被 M 持有 #
type p struct {
m muintptr
}
即当前 P 被这个 M 持有,如果当前的 M 被系统调用阻塞(即它运行的 G 进入了系统调用),运行时会将 M 与 P 分离开,重新找一个空闲的 M 或新建一个 M。
状态流转 #
type p struct {
status uint32
}
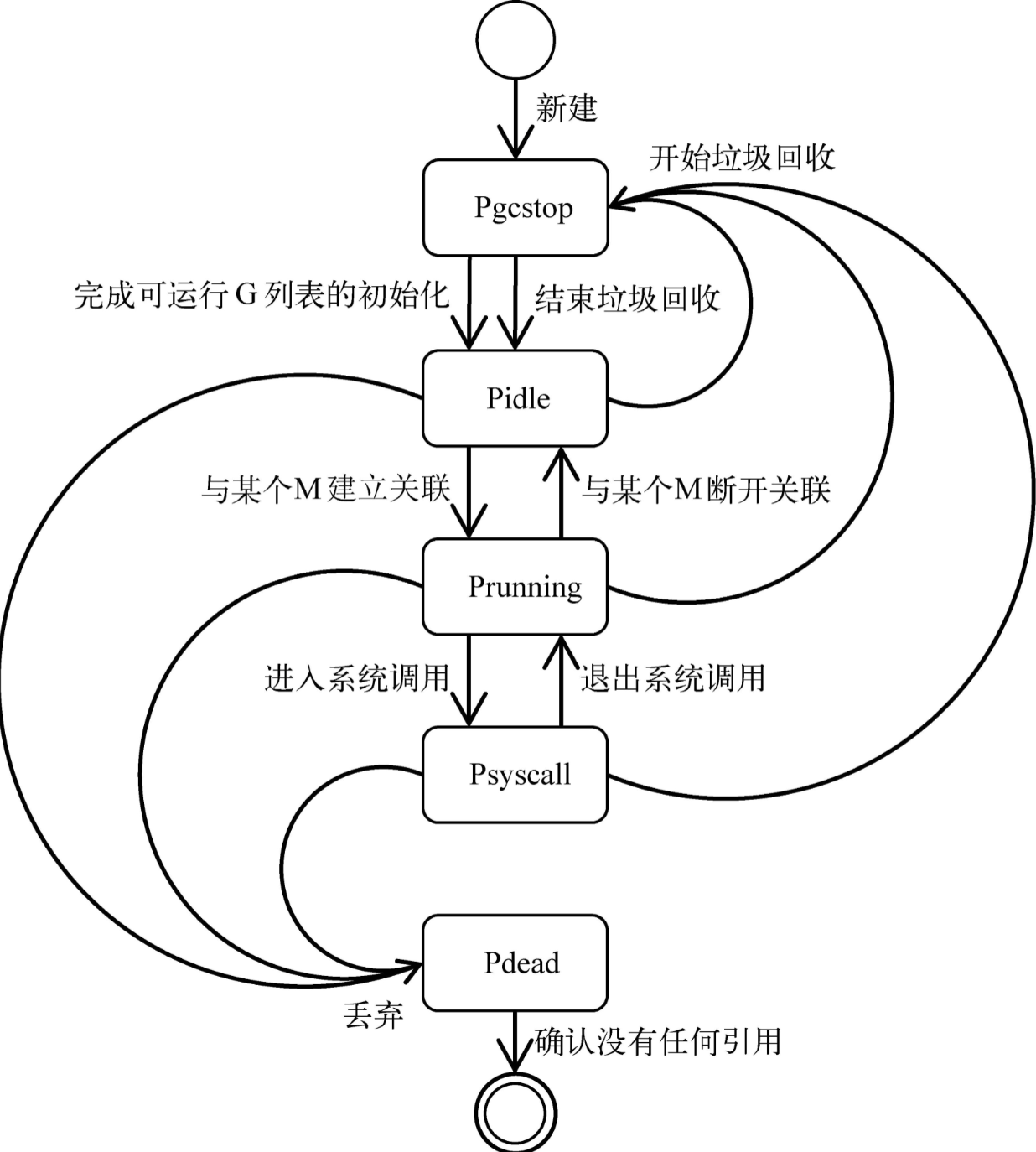
runtime.p 结构体中的状态 status 字段会是以下五种中的一种:
| 状态 | 描述 |
|---|---|
_Pidle | 处理器没有运行用户代码或者调度器,被空闲队列或者改变其状态的结构持有,运行队列为空。 |
_Prunning | 被线程 M 持有,并且正在执行用户代码或者调度器。 |
_Psyscall | 没有执行用户代码,当前线程陷入系统调用。 |
_Pgcstop | 被线程 M 持有,当前处理器由于垃圾回收被停止,是 P 的初始状态。 |
_Pdead | 当前处理器已经不被使用。 |
P 在各个状态之间的流转如图所示:
调度器 schedt #
type schedt struct {
lock mutex
midle muintptr // idle m's waiting for work
nmidle int32 // number of idle m's waiting for work
nmidlelocked int32 // number of locked m's waiting for work
mnext int64 // number of m's that have been created and next M ID
maxmcount int32 // maximum number of m's allowed (or die)
nmsys int32 // number of system m's not counted for deadlock
nmfreed int64 // cumulative number of freed m's
ngsys uint32 // number of system goroutines; updated atomically
pidle puintptr // idle p's
npidle uint32
// Global runnable queue.
runq gQueue
runqsize int32
// Global cache of dead G's.
gFree struct {
lock mutex
stack gList // Gs with stacks
noStack gList // Gs without stacks
n int32
}
// freem is the list of m's waiting to be freed when their
// m.exited is set. Linked through m.freelink.
freem *m
}
调度器是所有 goroutine 被调度的核心,存放了调度器持有的全局资源,其中访问这些资源需要持有锁:
- 管理了能够将 G 和 M 进行绑定的 M 队列
- 管理了空闲的 P 链表(队列)
- 管理了 G 的全局队列
- 管理了可被复用的 G 的全局缓存
- 管理了 defer 池
调度策略 #
Go 语言经历过多次版本迭代后,最终构成现在基于信号的抢占式调度器,其详细的演变历史可参考 Go 语言设计与实现 - 6.5 调度器。
调度器启动 #
schedinit #
Go 语言的运行时通过 schedinit 初始化调度器。
func schedinit() {
// raceinit must be the first call to race detector.
// In particular, it must be done before mallocinit below calls racemapshadow.
_g_ := getg()
sched.maxmcount = 10000
// The world starts stopped.
worldStopped()
moduledataverify()
stackinit()
mallocinit()
fastrandinit() // must run before mcommoninit
mcommoninit(_g_.m, -1)
cpuinit() // must run before alginit
alginit() // maps must not be used before this call
modulesinit() // provides activeModules
typelinksinit() // uses maps, activeModules
itabsinit() // uses activeModules
sigsave(&_g_.m.sigmask)
goargs()
goenvs()
parsedebugvars()
gcinit()
lock(&sched.lock)
sched.lastpoll = uint64(nanotime())
procs := ncpu
if n, ok := atoi32(gogetenv("GOMAXPROCS")); ok && n > 0 {
procs = n
}
if procresize(procs) != nil {
throw("unknown runnable goroutine during bootstrap")
}
unlock(&sched.lock)
// World is effectively started now, as P's can run.
worldStarted()
}
在初始函数执行的过程中会将能够创建的最大线程数 maxmcount 设置成 10000,可以使用 SetMaxThreads 函数设置 maxmcount,但是注意这个值不能小于 M 的数量,否则会引发 Panic,所以这个值越早设置风险越低。M 被创建之后会被加入全局 M 列表 runtime.allm。
procresize #
在 schedinit 最后调用了 procresize 来更新程序中处理器的数量,这个过程中不会运行任何用户 goroutine,调度器也会进入锁定状态。
func procresize(nprocs int32) *p {
assertLockHeld(&sched.lock)
assertWorldStopped()
old := gomaxprocs
maskWords := (nprocs + 31) / 32
// initialize new P's
for i := old; i < nprocs; i++ {
pp := allp[i]
if pp == nil {
pp = new(p)
}
pp.init(i)
atomicstorep(unsafe.Pointer(&allp[i]), unsafe.Pointer(pp))
}
_g_ := getg()
// g.m.p is now set, so we no longer need mcache0 for bootstrapping.
mcache0 = nil
// release resources from unused P's
for i := nprocs; i < old; i++ {
p := allp[i]
p.destroy()
// can't free P itself because it can be referenced by an M in syscall
}
var runnablePs *p
var int32p *int32 = &gomaxprocs // make compiler check that gomaxprocs is an int32
atomic.Store((*uint32)(unsafe.Pointer(int32p)), uint32(nprocs))
return runnablePs
}
procresize 函数会完成相应数量的处理器的启动,等待用户创建新的 goroutine 并为其调度处理器资源。
创建 goroutine #
goroutine 是通过 go 关键字创建的,编译器会将其在运行时转换为 newproc 函数调用。
newproc #
func newproc(siz int32, fn *funcval) {
argp := add(unsafe.Pointer(&fn), sys.PtrSize)
gp := getg()
pc := getcallerpc()
systemstack(func() {
newg := newproc1(fn, argp, siz, gp, pc)
_p_ := getg().m.p.ptr()
runqput(_p_, newg, true)
if mainStarted {
wakep()
}
})
}
newproc 的入参数,然后调用 newproc1 函数获取新的 goroutine 结构体,调用 runqput 将其加入处理器的运行队列并在满足条件时调用 wakep 唤醒新的处理器执行 goroutine。
newproc1 #
func newproc1(fn *funcval, argp unsafe.Pointer, narg int32, callergp *g, callerpc uintptr) *g {
_g_ := getg()
acquirem() // disable preemption because it can be holding p in a local var
_p_ := _g_.m.p.ptr()
newg := gfget(_p_)
if newg == nil {
newg = malg(_StackMin)
casgstatus(newg, _Gidle, _Gdead)
allgadd(newg) // publishes with a g->status of Gdead so GC scanner doesn't look at uninitialized stack.
}
if isSystemGoroutine(newg, false) {
atomic.Xadd(&sched.ngsys, +1)
}
casgstatus(newg, _Gdead, _Grunnable)
releasem(_g_.m)
return newg
}
newproc1会根据传入参数初始化一个 g 结构体,它实现的功能如下:
- 获取或者创建新的 goroutine 结构体;
- 将传入的参数移到 goroutine 的栈上;
- 更新 goroutine 调度相关的属性。
newproc1 会从处理器或者调度器的缓存中获取新的结构体,也可以调用 malg 函数创建。
运行队列 #
func runqput(_p_ *p, gp *g, next bool) {
if next {
retryNext:
oldnext := _p_.runnext
if !_p_.runnext.cas(oldnext, guintptr(unsafe.Pointer(gp))) {
goto retryNext
}
if oldnext == 0 {
return
}
// Kick the old runnext out to the regular run queue.
gp = oldnext.ptr()
}
retry:
h := atomic.LoadAcq(&_p_.runqhead) // load-acquire, synchronize with consumers
t := _p_.runqtail
if t-h < uint32(len(_p_.runq)) {
_p_.runq[t%uint32(len(_p_.runq))].set(gp)
atomic.StoreRel(&_p_.runqtail, t+1) // store-release, makes the item available for consumption
return
}
if runqputslow(_p_, gp, h, t) {
return
}
// the queue is not full, now the put above must succeed
goto retry
}
newproc 调用完 newproc1 获取完 goroutine 结构体会再调用 runqput 函数将 goroutine 放到运行队列上。Go 语言有两个运行队列,其中一个是处理器本地的运行队列,另一个是调度器持有的全局运行队列,只有在本地运行队列没有剩余空间时才会使用全局队列。
调度循环 #
调度器启动后会进入调度循环,经过 mstart、mstart1,最后的核心函数是 schedule,调度循环也是调度器工作的最核心逻辑。
schedule #
func schedule() {
_g_ := getg()
top:
var gp *g
var inheritTime bool
if sched.disable.user && !schedEnabled(gp) {
// Scheduling of this goroutine is disabled. Put it on
// the list of pending runnable goroutines for when we
// re-enable user scheduling and look again.
lock(&sched.lock)
if schedEnabled(gp) {
// Something re-enabled scheduling while we
// were acquiring the lock.
unlock(&sched.lock)
} else {
sched.disable.runnable.pushBack(gp)
sched.disable.n++
unlock(&sched.lock)
goto top
}
}
execute(gp, inheritTime)
}
schedule 通过以下几种方式查找可运行的 goroutine 并使用 execute 执行:
- 从全局运行队列查找待执行的 goroutine;
- 从 P 本地的运行队列查找待执行的 goroutine;
- 两种方法都没找到,会通过
findrunnable函数阻塞地进行查找 goroutine。
execute #
func execute(gp *g, inheritTime bool) {
_g_ := getg()
// Assign gp.m before entering _Grunning so running Gs have an
// M.
_g_.m.curg = gp
gp.m = _g_.m
casgstatus(gp, _Grunnable, _Grunning)
gp.waitsince = 0
gp.preempt = false
gp.stackguard0 = gp.stack.lo + _StackGuard
if !inheritTime {
_g_.m.p.ptr().schedtick++
}
// Check whether the profiler needs to be turned on or off.
hz := sched.profilehz
if _g_.m.profilehz != hz {
setThreadCPUProfiler(hz)
}
if trace.enabled {
// GoSysExit has to happen when we have a P, but before GoStart.
// So we emit it here.
if gp.syscallsp != 0 && gp.sysblocktraced {
traceGoSysExit(gp.sysexitticks)
}
traceGoStart()
}
gogo(&gp.sched)
}
找到可运行的 goroutine 后,交给 execute 函数准备执行 goroutine,然后 execute 会通过 gogo 函数将 goroutine 调度到当前线程上进行执行。
gogo #
gogo 是真正执行 goroutine,由汇编代码实现,在每种 CPU 平台的实现不一样,代码集中在 runtime.asm_xxx 里面。
// void gogo(Gobuf*)
// restore state from Gobuf; longjmp
TEXT runtime·gogo(SB), NOSPLIT, $8-4
MOVL buf+0(FP), BX // 获取调度信息
MOVL gobuf_g(BX), DX
MOVL 0(DX), CX // 保证 Goroutine 不为空
get_tls(CX)
MOVL DX, g(CX)
MOVL gobuf_sp(BX), SP // 将 runtime.goexit 函数的 PC 恢复到 SP 中
MOVL gobuf_ret(BX), AX
MOVL gobuf_ctxt(BX), DX
MOVL $0, gobuf_sp(BX)
MOVL $0, gobuf_ret(BX)
MOVL $0, gobuf_ctxt(BX)
MOVL gobuf_pc(BX), BX // 获取待执行函数的程序计数器
JMP BX
触发调度 #
触发 schedule 重新调度 goroutine 进行执行的场景主要有以下四种:
- 主动挂起,比如 channel 阻塞。
- 系统调用。
- 协作式调度,比如使用
Gosched函数。 - 系统监控。
线程调度 #
Go 语言的运行时会通过 runtime.startm 启动线程来执行处理器 P,如果我们在该函数中没能从闲置列表中获取到线程 M 就会调用 runtime.newm 创建新的线程。
总结 #
本文从操作系统的进程和线程的介绍开始,进而重新认识了协程,然后通过源码的相关数据结构对 MPG 调度模型的研究来了解 Groutine 运行时调度机制,除了源码,文章也参考了很多资料,列在了下面。另外本篇是着重参考了 Go 语言设计与实现 - 6.5 调度器 的研究思路和框架结构边学习边做笔记,捡我暂时能理解的内容产出了本文。