深入了解 Redis 的各种数据结构
8月 19, 2022
最近面试中发现我比较薄弱的地方还是在 Redis,很多数据结构对应的底层的原理不知道,于是来看看相关资料和源码,工作中没有这么深入研究过,惭愧了。
String #
使用方法 #
127.0.0.1:6379> set key value
OK
127.0.0.1:6379> set number 10086
OK
127.0.0.1:6379> set title "hello redis"
OK
127.0.0.1:6379> get key
"value"
127.0.0.1:6379> get number
"10086"
127.0.0.1:6379> get title
"hello redis"
底层结构 #
String 类型的底层的数据结构实现主要是 int 和 SDS(简单动态字符串),C 语言内置的 int 就不用介绍了,下面详细说一下 SDS。
简单动态字符串(SDS) #
SDS 使用 sds.h/sdshdr 结构来实现字符串 string 结构。其中 2.8 版本的实现如下:
struct sdshdr {
unsigned int len; //记录 SDS 所保存字符串的长度
unsigned int free; //记录 buf 数组中未使用字节的数量
char buf[]; // 字节数组,用于保存字符串
};
现在 7.0 的版本如下,基本上大同小异:
struct __attribute__ ((__packed__)) sdshdr8 {
uint8_t len; /* used */
uint8_t alloc; /* excluding the header and null terminator */
unsigned char flags; /* 3 lsb of type, 5 unused bits */
char buf[];
};
C 语言使用长度为 N+1 的字符数组来表示长度为 N 的字符串,并且字符数组的最后一个元素总是空字符 \0。这种方式不能满足 Redis 在安全性、性能、功能等方面的要求,具体来说,Redis 字符串有了 len 字段的加持下,有了更多优势:
- C 语言获取一个字符串的长度的时间复杂度为 $O(n)$,而 Redis 为 $O(1)$;
- C 语言的字符串拼接有可能造成缓冲区溢出问题,而 Redis 通过一定的空间分配策略,在拼接前会进行检查,并自动扩展,并且还会预分配额外空间,减少以后再次分配空间的次数。
- C 语言中频繁修改字符串意味着频繁分配内存空间,而 Redis 通过惰性空间释放优化策略来管理内存。
- C 语言只能保存文本数据,而 SDS 因为使用
len属性的值而不是\0来判断字符串是否结束,可以保存文本或二进制数据。
另外空间分配策略有公式可以参考,小于 1M 和大于 1M 的字符串分配内存空间的大小也不一样。
应用场景 #
缓存 #
对数据进行缓存是 Redis 最常见的用法之一,因为缓存操作是指把数据存储在内存而不是硬盘上,故访问内存远比访问硬盘的速度要快得多。
用户登陆 session #
在 Redis 存储 Session 可以解决分布式系统下 Session 的存储问题。
分布式锁 #
锁是一种同步机制,保证一项资源在任何时候只能被一个进程使用,如果有其他进行想要使用相同的资源,那么就必须等待,直到正在使用资源的进程放弃使用为止。我在之前的文章 Redis 的分布式锁使用 详细介绍过。
计数器 #
因为 Redis 处理命令是单线程,所以执行命令的过程是原子的。因此 String 数据类型适合计数场景,配合 INCR 命令,实现比如计算访问次数、点赞、转发、库存数量等等。
# 初始化文章的阅读量
> SET aritcle:readcount:1001 0
OK
#阅读量+1
> INCR aritcle:readcount:1001
(integer) 1
#阅读量+1
> INCR aritcle:readcount:1001
(integer) 2
#阅读量+1
> INCR aritcle:readcount:1001
(integer) 3
# 获取对应文章的阅读量
> GET aritcle:readcount:1001
"3"
限流器 #
为了保障系统的安全性和性能,并保证系统的重要资源不被滥用,应用程序常常会对用户的某些行为进行限制。实现这些限制机制的其中一种方法是使用限流器,它可以限制用户在指定时间段之内能够执行某项操作的次数。
限流器程序可以把操作的最大可执行次数存储在一个字符串键里面,然后在用户每次尝试执行被限制的操作之前,使用 DECR 命令将操作的可执行次数减 1,最后通过检查可执行次数的值来判断是否执行该操作。
List #
使用方法 #
127.0.0.1:6379> lpush L 0 1 2
(integer) 3
127.0.0.1:6379> lrange L 0 3
1) "2"
2) "1"
3) "0"
底层结构 #
在 3.2 之前,List 类型的底层数据结构是由 双向链表(adlist) 和 压缩列表(ziplist) 实现的。
默认情况下当列表的元素小于 512 个,且每个元素的值都小于 64 字节,Redis 会使用压缩列表,否则 Redis 会使用 adlist 作为 List 的底层数据结构。在 3.2 之后,List 的底层结构只由 quicklist 实现了,替换了 adlist 和 ziplist。
压缩列表(ziplist) #
虽然压缩列表在 7.0 被废弃了,但是了解一下也有点用。在特定情况下,Redis 曾经使用压缩列表作为 List 和 Hash 的底层结构。这个特定情况一般指的是包含的元素数量较少,且每个元素的大小也较小的时候。由此可见,压缩列表是 Redis 为了节约内存而开发的。
压缩列表是由一系列特殊的连续内存块组成的顺序型数据结构。一个压缩列表可以包含任意多个节点(entry),每个节点可以保存一个字节数组或者一个整数值,7.0 时的结构如下:
/* We use this function to receive information about a ziplist entry.
* Note that this is not how the data is actually encoded, is just what we
* get filled by a function in order to operate more easily. */
typedef struct zlentry {
unsigned int prevrawlensize; /* Bytes used to encode the previous entry len*/
unsigned int prevrawlen; /* Previous entry len. */
unsigned int lensize; /* Bytes used to encode this entry type/len.
For example strings have a 1, 2 or 5 bytes
header. Integers always use a single byte.*/
unsigned int len; /* Bytes used to represent the actual entry.
For strings this is just the string length
while for integers it is 1, 2, 3, 4, 8 or
0 (for 4 bit immediate) depending on the
number range. */
unsigned int headersize; /* prevrawlensize + lensize. */
unsigned char encoding; /* Set to ZIP_STR_* or ZIP_INT_* depending on
the entry encoding. However for 4 bits
immediate integers this can assume a range
of values and must be range-checked. */
unsigned char *p; /* Pointer to the very start of the entry, that
is, this points to prev-entry-len field. */
} zlentry;
/* Each entry in the ziplist is either a string or an integer. */
typedef struct {
/* When string is used, it is provided with the length (slen). */
unsigned char *sval;
unsigned int slen;
/* When integer is used, 'sval' is NULL, and lval holds the value. */
long long lval;
} ziplistEntry;
其中:
- 压缩列表可以包含多个节点,每个节点可以保存一个字节数组(
sval)或者一个整数值(lval)。 - 指针
p就是节点的起始地址,即prevrawlensize的值,通过每个节点的prevrawlensize可以计算出前一个节点的起始地址,也就是说压缩列表的遍历方向是从表尾向表头的。 len表示节点的数量。lensize表示压缩列表的总长。encoding记录了节点的属性所保存的数据类型。
创建一个 ziplist(即一个连续的内存块)的代码如下:
unsigned char *ziplistNew(void) {
unsigned int bytes = ZIPLIST_HEADER_SIZE+ZIPLIST_END_SIZE;
unsigned char *zl = zmalloc(bytes);
ZIPLIST_BYTES(zl) = intrev32ifbe(bytes);
ZIPLIST_TAIL_OFFSET(zl) = intrev32ifbe(ZIPLIST_HEADER_SIZE);
ZIPLIST_LENGTH(zl) = 0;
zl[bytes-1] = ZIP_END;
return zl;
}
插入新节点会通过对 ziplist 的不断 resize 进行扩容,从而获得可容纳新 entry 长度的 ziplist:
/* Resize the ziplist. */
unsigned char *ziplistResize(unsigned char *zl, size_t len) {
assert(len < UINT32_MAX);
zl = zrealloc(zl,len);
ZIPLIST_BYTES(zl) = intrev32ifbe(len);
zl[len-1] = ZIP_END;
return zl;
}
先根据 encoding 推断节点的编码类型,从而再根据 len 和 headersize 计算存储值的地址 sstr 或 sval:
unsigned int ziplistGet(unsigned char *p, unsigned char **sstr, unsigned int *slen, long long *sval) {
zlentry entry;
if (p == NULL || p[0] == ZIP_END) return 0;
if (sstr) *sstr = NULL;
zipEntry(p, &entry); /* no need for "safe" variant since the input pointer was validated by the function that returned it. */
if (ZIP_IS_STR(entry.encoding)) {
if (sstr) {
*slen = entry.len;
*sstr = p+entry.headersize;
}
} else {
if (sval) {
*sval = zipLoadInteger(p+entry.headersize,entry.encoding);
}
}
return 1;
}
添加新节点到压缩列表,或者从压缩列表中删除节点,可能会引发连锁更新操作,但这种操作出现的几率并不高,而且元素数量有上限,所以可以接受。
双向链表(adlist) #
这里再介绍下链表 adlist,它的全称为 A generic doubly linked list,adlist 提供了高效的节点重排能力,以及顺序性的节点访问方式,并且可以通过增删节点来灵活地调整链表的长度。除了列表 List,链表还被广泛用于实现 Redis 的各种功能,比如发布订阅、慢查询、监视器。
Redis 使用 adlist.h/listNode 结构来定义链表类型:
typedef struct listNode {
struct listNode *prev; // 前置节点
struct listNode *next; // 后置节点
void *value;
} listNode;
通过 adlist.h/list 来对链表进行管理:
typedef struct list {
listNode *head;
listNode *tail;
void *(*dup)(void *ptr);
void (*free)(void *ptr);
int (*match)(void *ptr, void *key);
unsigned long len;
} list;
其中:
- 链表是一个双向链表;
- 链表不是环形链表;
dup函数用于复制链表节点所保存的值;free函数用于释放链表节点所保存的值;match函数则用于对比链表节点所保存的值和另一个输入值是否相等。- 可以用于保存不同类型的值。
列表的最大长度为 2^32 - 1,也即每个列表支持超过 40 亿 个元素。
快速列表(quicklist) #
在 3.2 之后 Redis 的 List 结构就只由 quicklist 来实现:
typedef struct quicklistNode {
struct quicklistNode *prev;
struct quicklistNode *next;
unsigned char *entry;
size_t sz; /* entry size in bytes */
unsigned int count : 16; /* count of items in listpack */
unsigned int encoding : 2; /* RAW==1 or LZF==2 */
unsigned int container : 2; /* PLAIN==1 or PACKED==2 */
unsigned int recompress : 1; /* was this node previous compressed? */
unsigned int attempted_compress : 1; /* node can't compress; too small */
unsigned int extra : 10; /* more bits to steal for future usage */
} quicklistNode;
/* When quicklistNode->entry is compressed, node->entry points to a quicklistLZF */
typedef struct quicklistLZF {
size_t sz; /* LZF size in bytes*/
char compressed[];
} quicklistLZF;
可以看出,quicklist 是 listpack 和 adlist 的混合体,相对于链表它压缩了内存。
应用场景 #
栈 #
Redis 提供了 LPUSH 和 LPOP 、RPUSH 和 RPOP 命令,方便我们实现栈的特性。
消息队列 #
同样的,也可以通过 LPUSH + RPOP 命令实现队列的特性。另外也提供了 BRPOP 命令,BRPOP命令也称为阻塞式读取,客户端在没有读到队列数据时,自动阻塞,直到有新的数据写入队列,再开始读取新数据,不至于让消费者 CPU 一直执行 RPOP 命令。
待办事项 #
核心概念是使用两个列表来分别记录待办事项和已完成事项:
- 当用户添加一个新的待办事项时,程序就把这个事项放入待办事项列表中。
- 当用户完成待办事项列表中的某个事项时,程序就把这个事项从待办事项列表中移除,并放入已完成事项列表中。
分页 #
可以将给定的元素有序地放入一个列表中,然后使用 LRANGE 命令从列表中取出指定数量的元素,从而实现分页这一概念。
Hash #
使用方法 #
127.0.0.1:6379> hset m hello world
(integer) 1
127.0.0.1:6379> hlen m
(integer) 1
127.0.0.1:6379> hset m foo bar
(integer) 1
127.0.0.1:6379> hlen m
(integer) 2
127.0.0.1:6379> hgetall m
1) "hello"
2) "world"
3) "foo"
4) "bar"
127.0.0.1:6379> hget m hello
"world"
底层结构 #
字典经常作为一种数据结构内置在很多高级编程语言里,但是 C 语言没有实现字典这种数据结构,所以 Redis 构建了自己的字典实现,由压缩列表或哈希表实现。
默认情况下,如果哈希类型的元素小于 512 个,且值小于 64 字节,Redis 会使用压缩列表作为 Hash 类型的底层数据结构。如果不满足这两个条件,Redis 将会使用哈希表作为 Hash 类型的底层数据结构。
在 Redis 7.0 中,压缩列表数据结构已经废弃了,交由 listpack 数据结构来实现。
listpack #
7.0 之后 listpack 在哈希表实现中代替了 ziplist,先看看它的 entry 结构:
/* Each entry in the listpack is either a string or an integer. */
typedef struct {
/* When string is used, it is provided with the length (slen). */
unsigned char *sval;
uint32_t slen;
/* When integer is used, 'sval' is NULL, and lval holds the value. */
long long lval;
} listpackEntry;
unsigned char *lpNew(size_t capacity) {
unsigned char *lp = lp_malloc(capacity > LP_HDR_SIZE+1 ? capacity : LP_HDR_SIZE+1);
if (lp == NULL) return NULL;
lpSetTotalBytes(lp,LP_HDR_SIZE+1);
lpSetNumElements(lp,0);
lp[LP_HDR_SIZE] = LP_EOF;
return lp;
}
可以发现它的内存布局、实现原理和 ziplist 非常相似,比如都是连续的内存空间,listpack 底层仍然是使用和 ziplist 一样的 zmalloc 函数分配内存空间。
#define LP_HDR_SIZE 6 /* 32 bit total len + 16 bit number of elements. */
#define lpSetTotalBytes(p,v) do { \
(p)[0] = (v)&0xff; \
(p)[1] = ((v)>>8)&0xff; \
(p)[2] = ((v)>>16)&0xff; \
(p)[3] = ((v)>>24)&0xff; \
} while(0)
#define lpSetNumElements(p,v) do { \
(p)[4] = (v)&0xff; \
(p)[5] = ((v)>>8)&0xff; \
} while(0)
另外前端都有表示内存大小、元素个数的字段,尾部都有终结标志。不同于 ziplist 的是,在 listpack 中,每个列表项都只记录自己的长度,不会像 ziplist 的列表项会记录前一项的长度。所以在 listpack 中新增或修改元素,只会涉及到列表项自身的操作,不会影响后续列表项的长度变化,进而避免连锁更新。故 listpack 既可以从头部开始遍历也可以从尾部开始遍历。
哈希表(hashtable) #
前面已经介绍过了 ziplist 和 listpack,在 ziplist 或 listpack 中,每个 key 和 value 都会是一个节点 entry 进行组织,这里主要再说一下哈希表实现。哈希表使用 dict.h/dict 结构定义:
typedef struct dictEntry {
void *key;
union {
void *val;
uint64_t u64;
int64_t s64;
double d;
} v;
struct dictEntry *next; /* Next entry in the same hash bucket. */
void *metadata[]; /* An arbitrary number of bytes (starting at a
* pointer-aligned address) of size as returned
* by dictType's dictEntryMetadataBytes(). */
} dictEntry;
struct dict {
dictType *type;
dictEntry **ht_table[2];
unsigned long ht_used[2];
long rehashidx; /* rehashing not in progress if rehashidx == -1 */
/* Keep small vars at end for optimal (minimal) struct padding */
int16_t pauserehash; /* If >0 rehashing is paused (<0 indicates coding error) */
signed char ht_size_exp[2]; /* exponent of size. (size = 1<<exp) */
};
其中:
- 一个哈希表里面可以有多个哈希表节点,而每个哈希表节点就保存了字典中的一个键值对。
**ht_table是两个哈希表组成的数组,长度为 2 用于进行 rehash 时的空间交换。
哈希表使用哈希函数计算哈希值,不同的键小概率会有相同的哈希值,哈希表的碰撞冲突通常有拉链法和开放开放寻址法1,Redis 的哈希表使用拉链法来解决键冲突。被分配到同一个索引上的多个键值对会连接成一个单向链表。
随着操作的不断执行,哈希表保存的键值对会逐渐地增多或者减少,为了让哈希表的负载因子(loadfactor)维持在一个合理的范围之内,当哈希表保存的键值对数量太多或者太少时,程序需要对哈希表的大小进行相应的扩展或者收缩。扩展和收缩哈希表的工作可以通过执行 rehash(重新散列)操作来完成,Redis 对字典的哈希表执行 rehash 的步骤如下:
- 为字典的
ht_table[1]哈希表分配空间,这个哈希表的空间大小取决于要执行的操作,以及ht_table[0]当前的键值对数量; - 将保存在
ht_table[0]中所有的键值对 rehash 到ht_table[1]上面。 - 释放
ht_table[0],将ht_table[1]置为ht_table[0],并在ht_table[1]新建一个空白哈希表,为下一次 rehash 做准备。
rehash 逻辑具体具体可以参考 src/dict.c 下 dictRehash 这个函数:
int dictRehash(dict *d, int n)
rehash 过程并不是一次性地完成的,而是渐进式地完成的。
应用场景 #
短地址生成 #
散列表非常适合用来存储 短网址 ID 与 目标网址 之间的映射,所以我们可以基于 Redis 的散列实现一个短网址程序。
计数器 #
同样地,可以使用 HINCRBY 命令对指定的哈希的 field 计数。
127.0.0.1:6379> hset m count 10
(integer) 0
127.0.0.1:6379> HINCRBY m count 3
(integer) 13
常见的场景比如购物车调整数量。
Set #
使用方法 #
Set 类型是一个无序并唯一的键值集合,它的存储顺序不会按照插入的先后顺序进行存储。
127.0.0.1:6379> sadd s python java go
(integer) 3
127.0.0.1:6379> scard s
(integer) 3
底层结构 #
一个集合最多可以存储 2^32-1 个元素。Set 类型的底层数据结构是由哈希表或整数集合实现。默认情况下如果集合中的元素都是整数且元素个数小于 512 个,Redis 将使用整数集合作为 Set 的底层数据结构,如果不满足条件将使用哈希表作为 Set 类型的底层结构。
整数集合(intset) #
前面已经介绍过哈希表,这里再介绍一下整数集合。每个 intset.h/intset 结构表示一个整数集合:
typedef struct intset {
uint32_t encoding;
uint32_t length;
int8_t contents[];
} intset;
/* Note that these encodings are ordered, so:
* INTSET_ENC_INT16 < INTSET_ENC_INT32 < INTSET_ENC_INT64. */
#define INTSET_ENC_INT16 (sizeof(int16_t))
#define INTSET_ENC_INT32 (sizeof(int32_t))
#define INTSET_ENC_INT64 (sizeof(int64_t))
其中:
contents数组是整数集合的底层实现,各个项再数组中按值的大小从小到大有序排列,并且数组中不包含任何重复项。length属性记录了整数集合中包含的元素数量,即 contents 数组的长度。- 虽然 intset 结构将
contents属性声明为int8_t类型的数组,但实际上contents数组并不保存任何int8_t类型的值,contents数组的真正类型取决于encoding的值,其枚举在上面源码中。
因此,每当我们要将一个新元素添加到整数集合里面,并且新元素的类型比整数集合现有元素的类型都要长时,整数集合需要先进行升级(upgrade),然后才能将新元素添加到整数集合里面。
专门设计的升级机制有两个好处,一个是提升整数集合的灵活性,另一个是尽可能地节约内存。另外,整数集合不支持降级。
应用场景 #
唯一计数器 #
在前面对字符串键以及散列键已经展示过如何使用这两种键去实现计数器程序,但是在某些情况下,我们需要一种要求更为严格的计数器,这种计数器只会对特定的动作或者对象进行一次计数而不是多次计数,比如 PV 和 UV 的统计。
这个计数器通过把被计数的对象添加到集合来保证每个对象只会被计数一次,然后通过获取集合的大小来判断计数器目前总共对多少个对象进行了计数。
打标签 #
比如本站会对每一篇文章打标签(tag),一篇文章可以有多个标签,这些标签既可以对文章进行归类,又可以让用户快速地了解到文章要讲述的内容。
我们可以为不同的对象添加任意多个标签:同一个对象的所有标签都会被放到同一个集合里面,集合里的每一个元素就是一个标签。
点赞、投票 #
可以使用集合来存储对内容进行了点赞的用户,从而确保每个用户只能对同一内容点赞一次,并通过使用不同命令来实现查看点赞数量、查看所有点赞用户以及取消点赞等功能。
社交关系 #
微博、Twitter 都可以查看自己的关注名单和粉丝名单。程序为每个用户维护两个集合,一个集合存储用户的正在关注名单,而另一个集合则存储用户的关注者名单。
共同关注 #
Set 类型支持交集运算,所以可以用来计算共同关注的好友、公众号等。
比如,key 可以是用户 id,value 则是已关注的公众号的 id。uid:1 用户关注公众号 id 为 5、6、7、8、9,uid:2 用户关注公众号 id 为 7、8、9、10、11。
# uid:1 用户关注公众号 id 为 5、6、7、8、9
> SADD uid:1 5 6 7 8 9
(integer) 5
# uid:2 用户关注公众号 id 为 7、8、9、10、11
> SADD uid:2 7 8 9 10 11
(integer) 5
uid:1 和 uid:2 共同关注的公众号:
# 获取共同关注
> SINTER uid:1 uid:2
1) "7"
2) "8"
3) "9"
给 uid:2 推荐 uid:1 关注的公众号:
> SDIFF uid:1 uid:2
1) "5"
2) "6"
验证某个公众号是否同时被 uid:1 或 uid:2 关注:
> SISMEMBER uid:1 5
(integer) 1 # 返回0,说明关注了
> SISMEMBER uid:2 5
(integer) 0 # 返回0,说明没关注
抽奖 #
该场景中,可以把所有参与抽奖活动的玩家都添加到一个集合中,然后通过 SRANDMEMBER 命令随机地选出获奖者。
Zset #
Zset 类型(有序集合类型)相比于 Set 类型多了一个排序属性 score(分值),对于有序集合 Zset 来说,每个存储元素相当于有两个值组成的,一个是有序结合的元素值,一个是排序值。有序集合保留了集合不能有重复成员的特性(分值可以重复),但不同的是,有序集合中的元素可以排序。
使用方法 #
127.0.0.1:6379> zadd ranking 80 wang
(integer) 1
127.0.0.1:6379> zadd ranking 98 li
(integer) 1
127.0.0.1:6379> zscore ranking li
"98"
127.0.0.1:6379> ZREVRANGE ranking 0 1 withscores
1) "li"
2) "98"
3) "wang"
4) "80"
127.0.0.1:6379> ZRANGEBYLEX ranking - +
1) "wang"
2) "li"
底层结构 #
Zset 类型的底层数据结构是由压缩列表或跳表实现的,默认情况下,当有序集合的元素小于 128 个,并且每个元素的大小小于 64 字节时,Redis 会使用压缩列表作为 Zset 类型的底层数据结构。当然,7.0 以后 Zset 场景的压缩列表也被替换成了 listpack 来实现。
前面已经介绍过了压缩列表和 listpack,这里再介绍下跳表(skiplist)。
跳跃表(zskiplist) #
跳跃表(skiplist)是一种有序数据结构,它通过在每个节点中维持多个指向其他节点的指针,从而达到快速访问节点的目的。
zskiplist 的结构在 src/server.h 中被定义:
/* ZSETs use a specialized version of Skiplists */
typedef struct zskiplistNode {
sds ele;
double score;
struct zskiplistNode *backward;
struct zskiplistLevel {
struct zskiplistNode *forward;
unsigned long span;
} level[];
} zskiplistNode;
typedef struct zskiplist {
struct zskiplistNode *header, *tail;
unsigned long length;
int level;
} zskiplist;
typedef struct zset {
dict *dict;
zskiplist *zsl;
} zset;
其中:
zskiplist用于保存跳跃表信息(比如表头节点、表尾节点、长度)zskiplistNode用于表示跳跃表节点。zskiplist.level记录目前跳跃表内层数最大的那个节点的层数(表头节点除外)。层数即每次创建一个新跳跃表节点 Node 的时候,程序都根据幂次定律(power law,越大的数出现的概率越小)随机生成一个介于 1 和 32 之间的值作为 level 数组的大小,这个大小就是层的“高度”、“层数”。zskiplist.length记录跳跃表的长度即除头节点之外的节点数量。- 后退(
backward)指针指向位于当前节点的前一个节点,用于在程序从表尾向表头遍历时使用。 - 前进(
forward)指针用于表示指向表尾方向的前进指针,用于从表头 -> 表尾方向访问节点。 span用于记录两个节点之间的距离。- 在同一个跳跃表中,多个节点可以包含相同的分值,但每个节点的成员对象必须是唯一的。
- 跳跃表中的节点按照分值大小进行排序,当分值相同时,节点按照成员对象的大小进行排序。
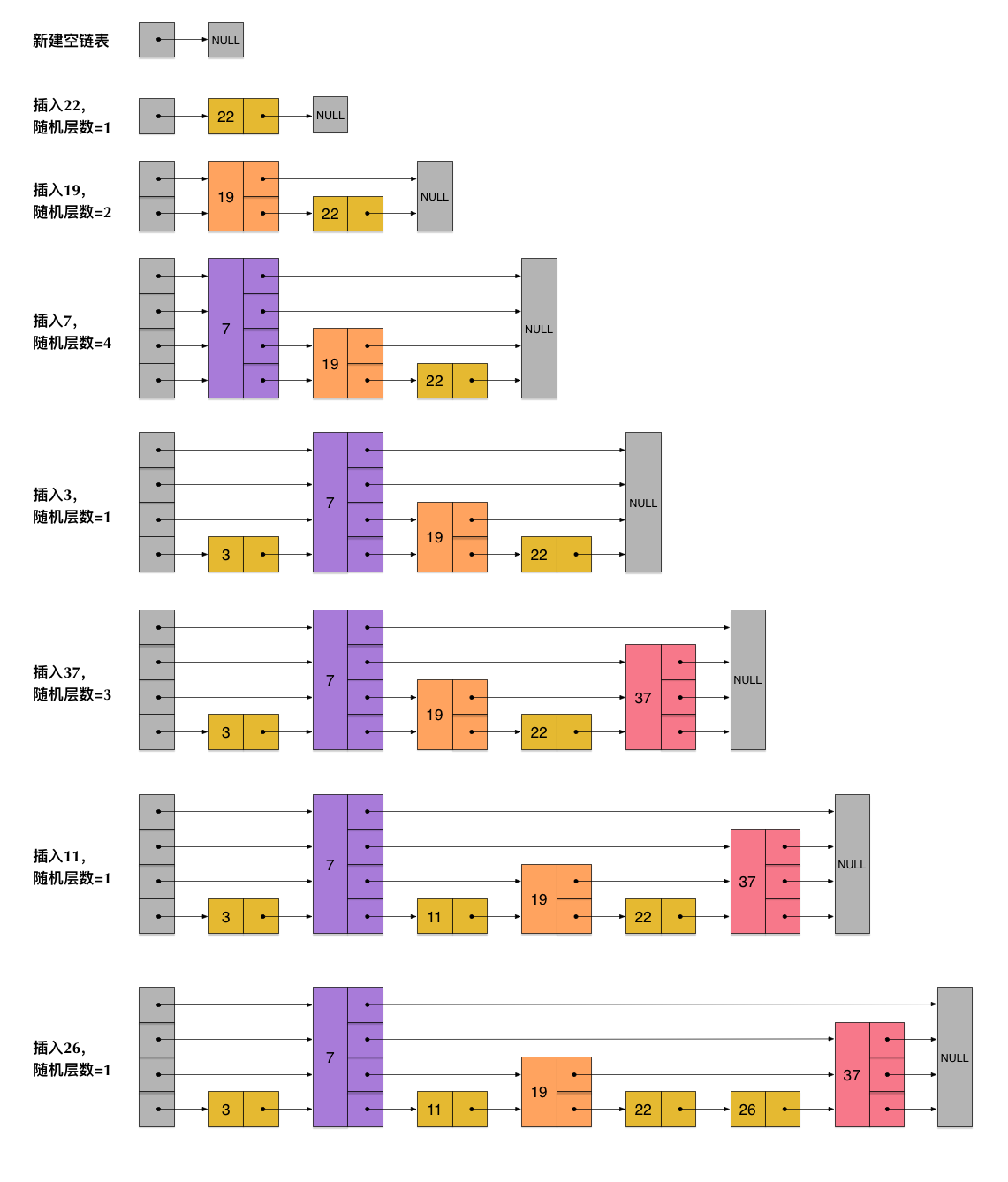
跳跃表支持平均 $O(logN)$、最坏 $O(N)$复杂度的节点查找,还可以通过顺序性操作来批量处理节点。在大部分情况下,跳跃表的效率可以和平衡树相媲美,并且因为跳跃表的实现比平衡树要来得更为简单,所以有不少程序都使用跳跃表来代替平衡树。
应用场景 #
排行榜 #
使用 ZADD 命令向排行榜中添加被排序的元素及其分数,并使用 ZREVRANK 命令去获取元素在排行榜中的排名,以及使用 ZSCORE 命令去获取元素的分数。
127.0.0.1:6379> zadd ranking 80 wang
(integer) 1
127.0.0.1:6379> zadd ranking 98 li
(integer) 1
127.0.0.1:6379> zadd ranking 60 zhao
(integer) 1
127.0.0.1:6379> zadd ranking 50 qian
(integer) 1
127.0.0.1:6379> zscore ranking li
"98"
127.0.0.1:6379> zscore ranking zhao
"60"
127.0.0.1:6379> ZREVRANK ranking li
(integer) 0
127.0.0.1:6379> ZREVRANGE ranking 0 2 withscores
1) "li"
2) "98"
3) "wang"
4) "80"
5) "zhao"
6) "60"
电话、姓名排序 #
使用有序集合的 ZRANGEBYLEX 或 ZREVRANGEBYLEX 命令可以帮助我们实现电话号码或姓名的排序,我们以 ZRANGEBYLEX (返回指定成员区间内的成员,按 key 正序排列,分数必须相同)为例。
我们可以将电话号码存储到 Zset 中,然后根据需要来获取号段:
> ZADD phone 0 13100111100 0 13110114300 0 13132110901
(integer) 3
> ZADD phone 0 13200111100 0 13210414300 0 13252110901
(integer) 3
> ZADD phone 0 13300111100 0 13310414300 0 13352110901
(integer) 3
获取所有号码:
> ZRANGEBYLEX phone - +
1) "13100111100"
2) "13110114300"
3) "13132110901"
4) "13200111100"
5) "13210414300"
6) "13252110901"
7) "13300111100"
8) "13310414300"
9) "13352110901"
获取 132 号段的号码:
> ZRANGEBYLEX phone [132 (133
1) "13200111100"
2) "13210414300"
3) "13252110901"
获取132、133号段的号码:
> ZRANGEBYLEX phone [132 (134
1) "13200111100"
2) "13210414300"
3) "13252110901"
4) "13300111100"
5) "13310414300"
6) "13352110901"
姓名排序:
> zadd names 0 Toumas 0 Jake 0 Bluetuo 0 Gaodeng 0 Aimini 0 Aidehua
(integer) 6
获取所有人的名字:
> ZRANGEBYLEX names - +
1) "Aidehua"
2) "Aimini"
3) "Bluetuo"
4) "Gaodeng"
5) "Jake"
6) "Toumas"
获取名字中大写字母A开头的所有人:
> ZRANGEBYLEX names [A (B
1) "Aidehua"
2) "Aimini"
获取名字中大写字母 C 到 Z 的所有人:
> ZRANGEBYLEX names [C [Z
1) "Gaodeng"
2) "Jake"
3) "Toumas"
时间线 #
比如博客系统、新闻系统都会按照文章发布时间的先后,把最近发布的文章放在最前面,发布较早的文章则放在后面。
要设计这样的系统,可以将时间线里面的元素用作成员,与元素相关联的时间戳用作分值,将元素和它的时间戳添加到有序集合中。通过 ZREVRANGE 命令或者 ZREVRANGEBYSCORE 实现以分页的方式按顺序取出时间线中的元素,或者从时间线中取出指定时间区间内的元素。
商品推荐 #
在浏览网上商城的时候,我们常常会看到类似“购买此商品的顾客也同时购买”这样的商品推荐功能。
针对这种场景,可以设计一个程序,为每一个商品维护一个 Zset 集合。如果用户在对一个商品执行了浏览或者购买操作之后,也对另一个商品执行了相同的操作,那么程序就对这次操作的访问路径进行记录和计数,然后可以通过计数结果来知道用户们一般在对指定目标执行了某个操作之后,还会对哪些目标执行相同的操作。
自动补全 #
自动补全和商品推荐类似,同样为一个关键字维护一个 Zset 集合,当输入一个关键字后,根据集合中的权重进行补全推荐。
Redis 对象系统 #
前面知道了 Redis 的几种外部数据结构的底层实现,但是 Redis 并没有直接使用这些数据结构来实现键值对数据库,而是基于底层数据结构(比如 ziplist、quicklist、listpack、skiplist)构建了一个对象系统,这个系统包含字符串对象、列表对象、哈希对象、集合对象和有序集合对象等。
Redis 中的每个对象都由一个 server.h/redisObject 结构表示:
struct redisObject {
unsigned type:4;
unsigned encoding:4;
unsigned lru:LRU_BITS; /* LRU time (relative to global lru_clock) or
* LFU data (least significant 8 bits frequency
* and most significant 16 bits access time). */
int refcount;
void *ptr;
};
type #
对象的 type 属性记录了对象的类型,这个属性的值可以是下面给出的常量的一种:
/* server.h */
/* The actual Redis Object */
#define OBJ_STRING 0 /* String object. */
#define OBJ_LIST 1 /* List object. */
#define OBJ_SET 2 /* Set object. */
#define OBJ_ZSET 3 /* Sorted set object. */
#define OBJ_HASH 4 /* Hash object. */
type 命令的实现如 getObjectTypeName 所示:
/* db.c */
char* getObjectTypeName(robj *o) {
char* type;
if (o == NULL) {
type = "none";
} else {
switch(o->type) {
case OBJ_STRING: type = "string"; break;
case OBJ_LIST: type = "list"; break;
case OBJ_SET: type = "set"; break;
case OBJ_ZSET: type = "zset"; break;
case OBJ_HASH: type = "hash"; break;
case OBJ_STREAM: type = "stream"; break;
case OBJ_MODULE: {
moduleValue *mv = o->ptr;
type = mv->type->name;
}; break;
default: type = "unknown"; break;
}
}
return type;
}
encoding #
对象的 ptr 指针指向对象的底层实现的数据结构,而这些数据结构按什么编码(比如是 listpack 还是 skiplist)由 encoding 来指定:
/* Objects encoding. Some kind of objects like Strings and Hashes can be
* internally represented in multiple ways. The 'encoding' field of the object
* is set to one of this fields for this object. */
#define OBJ_ENCODING_RAW 0 /* Raw representation */
#define OBJ_ENCODING_INT 1 /* Encoded as integer */
#define OBJ_ENCODING_HT 2 /* Encoded as hash table */
#define OBJ_ENCODING_ZIPMAP 3 /* No longer used: old hash encoding. */
#define OBJ_ENCODING_LINKEDLIST 4 /* No longer used: old list encoding. */
#define OBJ_ENCODING_ZIPLIST 5 /* No longer used: old list/hash/zset encoding. */
#define OBJ_ENCODING_INTSET 6 /* Encoded as intset */
#define OBJ_ENCODING_SKIPLIST 7 /* Encoded as skiplist */
#define OBJ_ENCODING_EMBSTR 8 /* Embedded sds string encoding */
#define OBJ_ENCODING_QUICKLIST 9 /* Encoded as linked list of listpacks */
#define OBJ_ENCODING_STREAM 10 /* Encoded as a radix tree of listpacks */
#define OBJ_ENCODING_LISTPACK 11 /* Encoded as a listpack */
每种类型的对象都至少使用了两种不同的编码,比如:
- String 由 int 或 SDS 实现;
- List 由 ziplist 或 quicklist 实现;
- Hash 由 listpack 或 hashtable 实现;
- Set 由 intset 或 hashtable 实现;
- Zset 由 listpack 或 zskiplist 实现;
LRU #
与缓存淘汰机制相关,以后再详细说。
refcount #
因为 C 语言并不具备自动内存回收功能,所以 Redis 在自己的对象系统中构建了一个引用计数(reference counting)技术实现的内存回收机制,通过这一机制,程序可以通过跟踪对象的引用计数信息,在适当的时候自动释放对象并进行内存回收。
总结 #
一方面,我们可以通过 Redis 看看如何对 C 语言中“缺失”的数据结构进行实现,在以后使用其他高级语言自带的高级数据结构时,也可以对底层的实现有一个抽象的认识。
另一方面,查阅资料发现,基本上 Redis 实现的所有结构在版本的进化中都有微调甚至整体替换,比如哈希表由之前的压缩列表替换成了 7.0 的 listpack,列表也由之前的双向链表变成了 quicklist 实现,不禁想要提醒下面试官们,这玩意儿的答案也是与时俱进的哦~