数据库的索引
10月 29, 2021
索引在数据库中的地位非常重要,只有搞明白索引,才有可能在日常的数据库相关工作中解决实际问题:提高库表设计能力、优化查询效率、提升数据库性能等核心问题。数据库的索引有哪些?以 MySQL 的 InnoDB 存储引擎为例,一般可分为聚集索引、辅助索引、全文索引、哈希索引。但是只说这些可能还不够,因为你应该还听说过主键索引、联合索引、唯一索引,甚至自适应哈希索引等等,他们都称为索引,只是通常描述的维度不一样,下面会逐渐区分开。本文就先从索引在数据结构上的实现开始说起。
B+ 树 #
我们都知道 InnoDB 的索引是用 B+ 树实现的,我们先看下 B+ 树的特点:
- 数据只出现在叶子节点
- 叶子结点之间有双向链表来保持有序。
相对的,B 树的特点我也列一下:
- B 树的每个结点都存储了数据。
- 叶子接点之间没有指针相邻。
总结起来,即 B 树因为叶子结点之间没有链表连接,查询一个范围的 SQL 只能通过树的遍历逐个结点来查找匹配,这个遍历次数会随着查询结果的多少而显著变化,而且目标结点之间在磁盘上可能不是连续存放的,所以只能是随机 IO。再看 B+ 树,在数据库中,B+ 树的高度一般在 2~4 层,也就是说查找一行记录最多只需要 2 到 4 次 IO,然后叶子结点之间可以通过链表依次连接,我们在拿到一个叶子结点的时候就可以直接顺序 IO 遍历树的全部数据了,所以说 B+ 树的查询效率在关系型数据库的场景里面大多相比 B 树来说更加稳定。
B+ 树和表有什么关系?我们再把镜头拉远一点。
数据的逻辑存储 #
谈索引之前还要先说一下,InnoDB 存储引擎是索引组织表,也就是说表的内容是按照键的顺序存放的。所以索引和表是什么关系呢?B+ 树的叶子结点存储的是数据页,而页是 InnoDB 管理存储空间的基本单位,从表到页经历了好几层的维度,分别是:表空间、段、区、页有时也叫块(block),页的里面还有行。
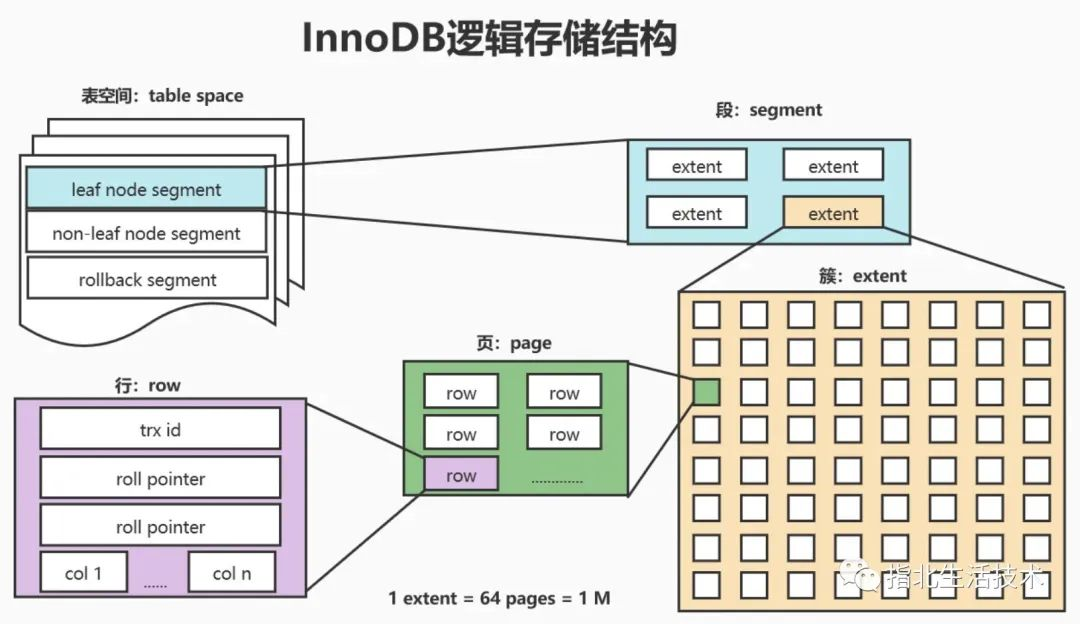
表空间(tablespace) #
表空间是 InnoDB 逻辑结构的最高层,每个表的数据根据参数配置可以单独放到一个表空间。
段(segment) #
表空间是有各个段组成的,常见的段有:数据段、索引段、回滚段等。因为是索引组织表,这里的数据段是指 B+ 树的叶子结点,索引段是 B+ 树的非叶子结点。
区(extent) #
区是由连续页组成的空间,在任何情况下每个区的大小都为1MB。为了保证区中页的连续性,InnoDB存储引擎一次从磁盘申请4~5个区。在默认情况下,InnoDB存储引擎页的大小为16KB,即一个区中一共有64个连续的页。
页(page) #
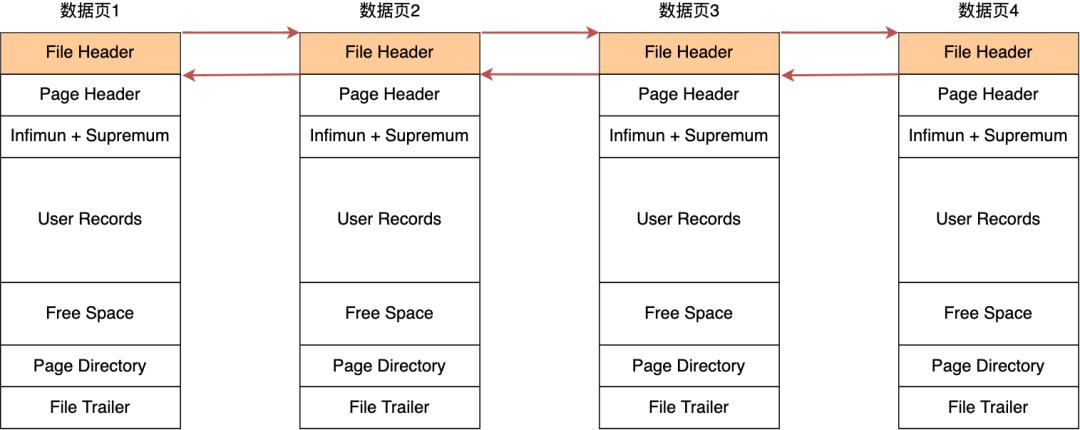
页是 InnoDB 管理存储空间的基本单位,在 B+ 树中每个节点都是一个数据页(也叫索引页,枚举类型是 FIL_PAGE_INDEX,当然还有其他类型的页),一个页的 user_record 结构里面可以存储多个行。叶子节点的页用来存放数据项,非叶子结点中用来存放目录项,数据库通过把页读入内存,再在内存中查找,最后得到想要查询的数据。
行(row) #
行在页里是按照单向链表存放的,通过行上面的 next_record 记录来存放下一个行的地址,链表的头结点是页上面的 infimum,尾结点是页的 supremum,这两个结点同时象征着按主键顺序排列的负无穷和正无穷(最小值和最大值)。
行记录的 record_type枚举值:
- 普通的用户记录
- 目录项记录
- Infinum 记录
- Supremum 记录
OK,有了这些基本的概念,我们可以说开始说索引了。
聚集索引 #
聚集索引就是按照主键的顺序构造一个 B+ 树,并在叶子结点中存放表的行记录数据,一个表只有一个主键,所以只能有一个聚集索引。行记录之间在物理存储上并不是按照顺序连续存放的,而是通过行记录的 next_record 指针以链表形式存在的。
如果一个表没有显示定义主键,InnoDB 会判断表中是否有非空的唯一索引,并根据定义索引的顺序选择一列为主键,如果还没有,InnoDB 会自动创建一个。
辅助索引 #
辅助索引也叫二级索引,和聚集索引结构一样都是 B+ 树,聚集索引和辅助索引最大的区别是,聚集索引的叶子节点的行记录里,存放着一个行记录的全部信息,而辅助索引只存放着索引相关的字段。
联合索引 #
联合索引也叫做复合索引或多列索引,本质上也是一个二级索引,故联合索引也是通过 B+ 树组织的。如联合索引(c1, c2),在叶子节点上,各条记录是先按照 c1 的大小进行排序,然后按照 c2 的顺序进行排序,三个列时也一样,以此类推。
通过 SQL 中创建一条联合索引:
CREATE INDEX <索引的名字> ON tablename (字段名1,字段名2...);
ALTER TABLE tablename ADD INDEX [索引的名字] (字段名1,字段名2...); 常用
CREATE TABLE tablename ( [...], INDEX [索引的名字] (字段名1,字段名2...) );
全文索引 #
对于下面这样的查询,B+ 树是不太能满足功能需要的,即使满足功能情况下性能也很差。全文索引的引入就是为了解决这个问题。
SELECT * FROM blog WHERE content like '%xxx%';
MySQL 数据库通过 MATCH()…AGAINST() 语法支持全文检索的查询,MATCH指定了需要被查询的列,AGAINST指定了使用何种方法去进行查询。
select * from test where match(column_name) against('query_str');
通过 SQL 创建一个全文索引:
CREATE FULLTEXT INDEX <索引的名字> ON tablename (字段名);
ALTER TABLE tablename ADD FULLTEXT [索引的名字] (字段名);
CREATE TABLE tablename ( [...], FULLTEXT KEY [索引的名字] (字段名) ;
自然语言的全文索引 #
全文索引默认有两种模式,默认是自然语言模式,自然语言模式不能使用操作符,不能指定关键词必须出现或者必须不能出现等复杂查询。
SELECT * FROM tablename
WHERE MATCH (title)
AGAINST('title_name' IN NATURAL LANGUAGE MODE);
IN NATURAL LANGUAGE MODE 默认可不填。
布尔全文索引 #
在布尔搜索中,我们可以在查询中自定义某个被搜索的词语的相关性,当编写一个布尔搜索查询时,可以通过一些前缀修饰符来定制搜索。
- + 必须包含该词
- - 必须不包含该词
- > 提高该词的相关性,查询的结果靠前
- < 降低该词的相关性,查询的结果靠后
- (*)星号 通配符,只能接在词后面
SELECT * tablename WHERE MATCH(content) AGAINST('a*' IN BOOLEAN MODE);
哈希索引 #
在 InnoDB 中一般指的是自适应哈希索引,也是采用哈希表的实现方法,特别适合在 where id = xxx 这样的等值查询中。与其他索引不同的是,自适应哈希索引是数据库自身创建并使用的,用户不能进行干预。
唯一索引 #
一直觉得唯一索引很尴尬,前有唯一约束,后有主键索引,我们看看他们的区别。
唯一索引和主键索引的区别 #
首先,主键索引是一个特殊的唯一索引。在使用层面,有一些区别:
- 主键一定是唯一索引,唯一索引不一定是主键。
- 唯一索引允许存在空值,主键不可以。
- 一个表可以有多个唯一索引,但是主键索引只有一个。
唯一索引和唯一约束的区别? #
唯一索引和唯一约束都可以多个 NULL 值并存。还有一些区别:
- 创建唯一约束,会自动创建一个同名的唯一索引,该索引不能单独删除,删除约束会自动删除索引。唯一约束是通过唯一索引来实现数据的唯一。
- 创建一个唯一索引,这个索引就是独立,可以单独删除。
- 如果表的一个字段,要作为另外一个表的外键,这个字段必须有唯一约束(或是主键),如果只是有唯一索引,就会报错。
常见问题 #
查看索引 #
SHOW INDEX FROM table_xxx;
结果的字段含义可以直接参考 这里 。
执行计划 #
执行计划是 MySQL 如何执行一条 SQL 语句,包括 SQL 查询的顺序、是否使用索引、以及使用的索引信息等内容,我们通过 Explain 查看执行计划。这篇博客 写的相当详细,我就不复制粘贴了。
回表 #
先通过二级索引拿到主键 id,然后再通过聚集索引拿到全部行数据,这样的步骤就是回表。
索引覆盖 #
只需要在一棵索引树上就能获取 SQL 所需的所有列数据,无需回表,这样的操作就是索引覆盖。Explain 的输出结果 Extra 字段为 Using index 时,能够触发索引覆盖。