Spark 是内存密集型的分布式大数据计算引擎。Apache Spark™ is a multi-language engine for executing data engineering, data science, and machine learning on single-node machines or clusters1.
Spark 生态圈以 Spark Core 为核心,支持从 HDFS、Amazon S3、HBase、ElasticSearch、MongoDB、MySQL、Kafka 等多种数据源读取数据。同时,Spark 支持以 Standalone、Hadoop YARN、Apache Mesos、Kubernetes 为资源管理器调度任务,从而完成 Spark 应用程序的计算任务。
搭建环境 #
首先,去官网下载 Spark,下载下来的 Spark 文件中,常见的目录有 bin、 sbin、kubernetes、data、examples,其中 bin 里面有 pyspark 、spark-submit 、spark-sql 等常用的命令。以 Python 为例,启动 ./bin/pyspark 后,可以在 Python Shell 中执行一些 Spark 操作, 通过访问 http://localhost:4040 可以浏览 Spark UI 界面。
相关概念 #
使用之前还需要了解一些基本概念。
驱动器和执行器
SparkSession
可以存在多个 SparkSession 用于连接多个不同的数据库。
执行计划 #
应用
作业
RDD
DataFrame
Job
Spark 会将一个应用依次划分为作业、执行阶段和任务。Jobs 标签页和 Stages 标签页让我们能够按照这种划分层级查看应用的执行情况,最低以单个任务为粒度查看详情。我们可以看到各粒度下的完成状态、I/O 相关指标、内存消耗、执行持续时间等信息。
Stages
通过 Stages 标签页可以概览所有作业中的所有执行阶段的当前状态。
Executors
Executors 标签页提供了应用创建的所有执行器的信息。
转化操作和行动操作 #
所有 Spark 对数据的操作可以分为两种:转化操作(transformation)和行动操作(action)。
所有的转化操作都是惰性的,比如 select() 和 filter() 这样的操作不会改变原有的 DataFrame,这些操作只会将转化结果作为新的 DataFrame 返回。惰性意味着不会立即计算结果,而是将转化关系作为血缘(lineage) 记录下来,这将帮助 Spark 在最终生成执行计划时进行合并或优化,从而提高执行效率。
而行动操作会触发实际求值,包括之前所积累下的转化操作。
窄转化和宽转化 #
转化操作可以分为两类,根据依赖关系可以判断是属于窄转化还是宽转化。
如果输出中的单个数据分区是由单个输入分区计算得来的,那么这样的转化操作就称为窄转化,比如 select() 和 filter() 这样的方法就属于窄转化,因为它们在每个数据分区上的操作是独立的,生成输出的数据分区时不需要跨分区交换任何数据。
宽转化是要从其他分区读取数据并进行整合,可能要写入硬盘,比如 groupBy() 和 orderBy() 就会产生宽转化操作。
DAG #
Spark 将每个任务构造成 DAG(Directed Acyclic Graph,有向无环图)来执行,其内部计算过程是基于 RDD(Resilient Distributed Dataset,弹性分布式数据集)在内存中对数据进行迭代计算的,因此运行效率很高。
RDD #
RDD(Resilient Distributed Dataset,弹性分布式数据集) 是 Spark 1.0 时期的底层数据对象。
API #
Spark SQL #
pyspark.sql.dataframe.DataFrame
Pandas API on Spark #
pyspark.pandas.frame.DataFrame
DataSet #
DataSet 也是 Spark 1.6 加入的 feature。
A DataFrame is a Dataset organized into named columns, DataFrame is represented by a Dataset of Rows. The Dataset API is available in Scala and Java. 并没有针对 Python 提供 DataSet 接口。
Spark 2.0 用相似的接口统一了 DataFrame API 和 Dataset API。
DataFrame 没法做到强类型检查,而编译型语言 Scala 和 Java 可以,所以 DataSet 相对于 DataFrame 提供了强类型支持。
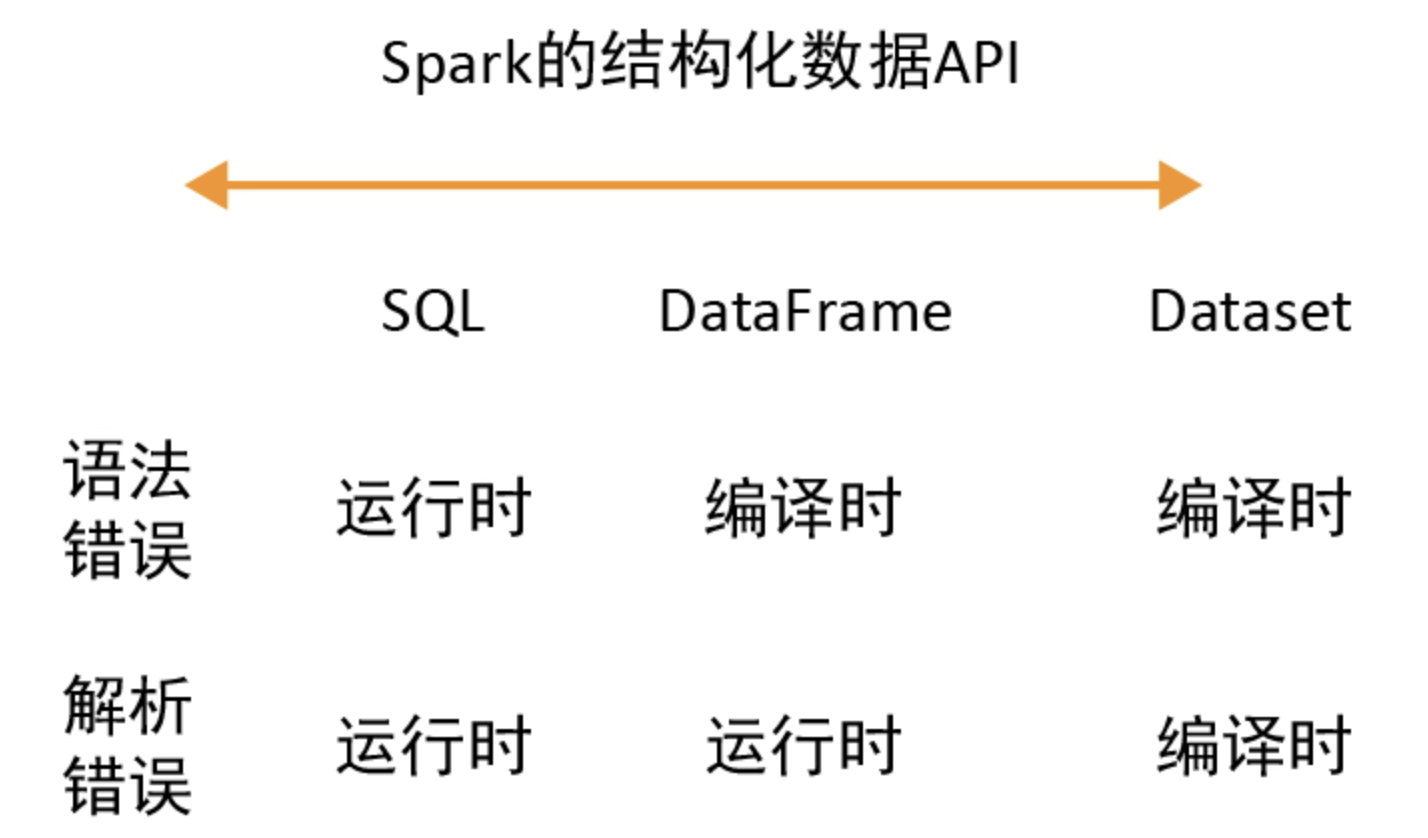
SQL、DataFrame 和 DataSet 区别 #
DataFrame 和 Dataset 都是基于 RDD 构建的
https://raw.githubusercontent.com/tcitry/static/master/2023/biJN7A.png
{kind=link}
Spark 3.0 中有两种 DataFrame。PySpark 中默认的 DataFrame 其实是 Spark SQL 的 pyspark.sql.dataframe.DataFrame,这个 DataFrame 可以通过接口 pyspark.sql.DataFrame.pandas_api 转换为 pyspark.pandas.frame.DataFrame。
底层引擎 #
上层的 DataFrame API 和 DataSet API 都是由底层的 Spark SQL 引擎支撑的,Spark SQL 引擎的核心是 Catalyst 优化器和 Tungsten 项目。两者共同支撑着高层的 DataFrame API 和 Dataset API,以及 SQL 查询。
优化过程都是一样的:先是构建逻辑计划,接着是生成物理计划,最后是生成紧凑的二进制代码。
执行计划 #
Spark SQL #
Spark 允许创建两种表,有管理表和无管理表。有管理表既管理元数据,有管理文件存储上的数据。无管理表只能删除元数据,无法删除实际数据。
us_flights_df = spark.sql("SELECT * FROM us_delay_flights_tbl")
us_flights_df2 = spark.table("us_delay_flights_tbl")
repartition
部署模式 #
Spark Standalone
Mesos
YARN
Kubernetes
命令行 #
spark-shell
spark-submit
其他支持 #
Structured Streaming 流数据处理
MLlib 机器学习库
参考文档 #
Spark 2.2.x 中文官方参考文档
https://spark-reference-doc-cn.readthedocs.io/zh_CN/latest/index.html
SparkBy{Examples}
https://sparkbyexamples.com/pyspark-tutorial/
Spark 编程指南
https://doc.yonyoucloud.com/doc/spark-programming-guide-zh-cn/index.html
一些代码示例:
Spark 官网 https://spark.apache.org ↩︎